목차 열기
503 트러블슈팅 핵심 스토리
"DB가 한가한데 왜 503?" — 커넥션 풀 병목의 진짜 원인을 찾아간 발표용 스토리라인
핵심 한 줄 메시지
"DB 인스턴스 업그레이드(돈)로 해결할 수도 있었지만, 원인을 파고드니 사양 문제가 아니라 앱이 쿼리를 너무 많이 보내는 문제였다. 그래서 앱단 최적화로 해결했다."
기 — 증상부터 시작
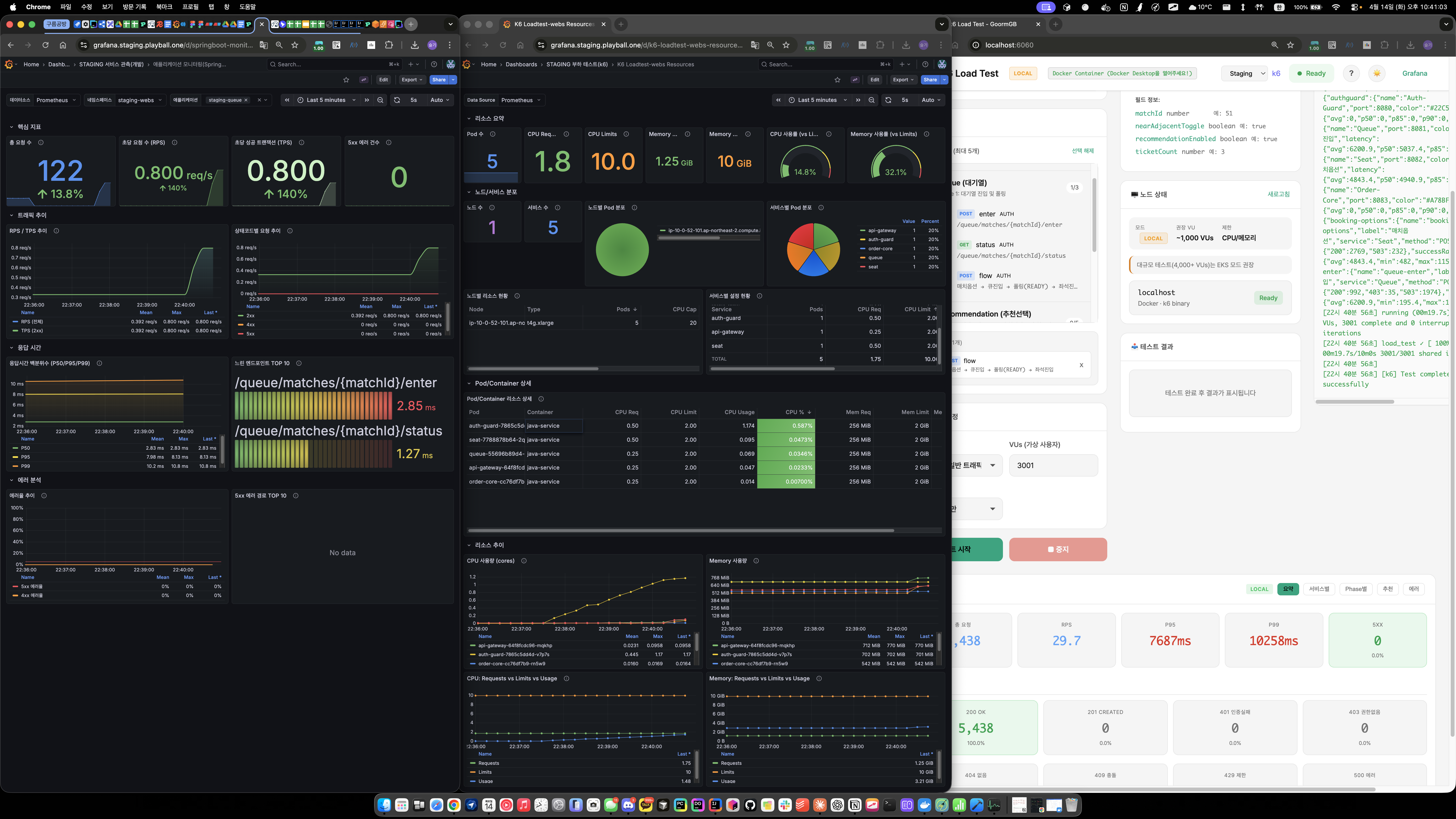
부하테스트에서 발견된 문제
- 3,000 VU 스트레스 테스트 —
upstream connect error / connection timeout503 에러 지속 발생 - k6 결과: P99 6~7초, 503 발생률 1~2%
- Queue P95 6,544ms / 503 40건
- Seat P95 6,177ms / 503 18건
4,000 VU에서는 시스템 자체가 죽음
503 대량 + k6 툴 자체가 종료
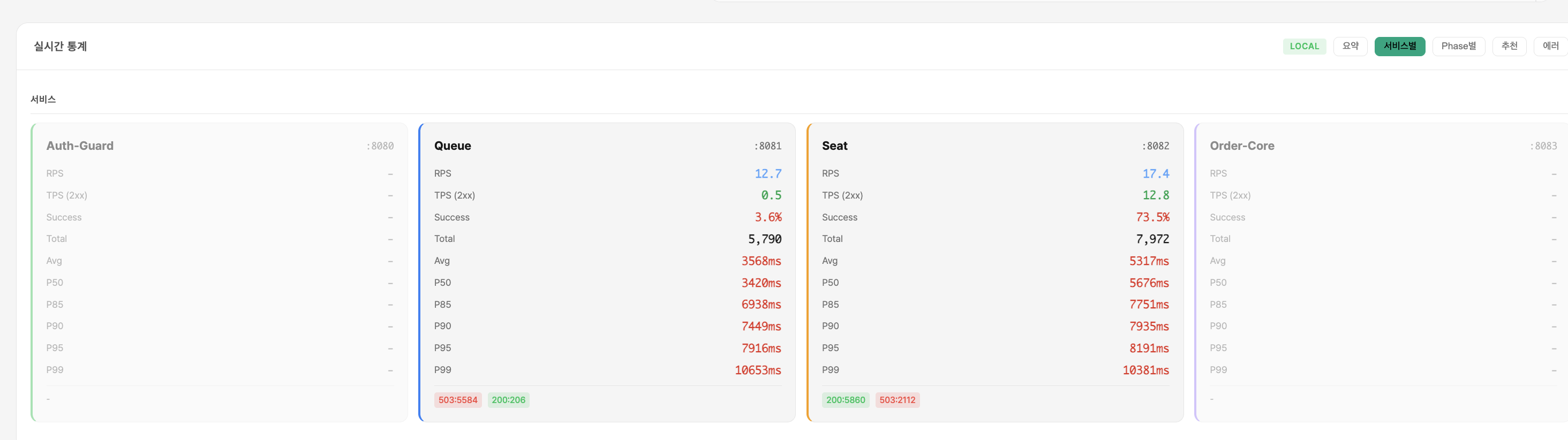
일반적인 반응
"DB가 부족한가? 인스턴스 업그레이드해야 하나?"
승 — 그런데 DB는 놀고 있었다
이 부분이 발표의 반전 포인트입니다.
RDS 모니터링 결과
- CPU 10%
- Memory 25%
- Connections: 한계 270 도달
→ DB 자체는 여유. 문제는 DB 처리 능력이 아니다.
"그럼 뭐가 문제지?" → 병목 추적 시작
전 — 진짜 범인은 커넥션 풀
관찰된 지표
- Tomcat 스레드 peak 735
- HikariCP pending 48 (커넥션 대기열 누적)
모순처럼 보이는 상황: DB는 한가한데 앱은 커넥션 획득만 기다리고 있었습니다. 하지만 이건 자연스러운 현상입니다.
왜 이런 일이 일어나는가
1. DB max_connections: 250 (db.t4g.medium, RDS 공식 LEAST(DBInstanceClassMemory/9531392, 5000) 기준)
2. 동시 요청: 3,000 VU → Tomcat 스레드 수백 개가 커넥션 요청
3. 각 요청이 짧은 쿼리를 여러 번 날림
├─ Match 조회 (booking-options 저장 시 1번)
├─ Section 조회 (좌석맵 진입 시 1번)
├─ Block 조회 (좌석맵 진입 시 1번)
├─ User 조회 (모든 인증 경로)
└─ Onboarding 조회 (추천 계산 시 1번)
4. 쿼리 자체는 빠르지만(5~30ms), 커넥션을 잠깐씩 잡았다 놓는 횟수가 너무 많음
5. 풀 포화 → 스레드 대기 → 타임아웃 → Envoy가 503 반환인과관계 도식
쿼리 많음 → 커넥션 짧게 자주 잡음 → 풀 포화 → Tomcat 스레드 대기 → accept-queue 포화 → 503
↑
여기를 끊는다 (Caffeine 캐시)결 — 해결: 쿼리 횟수를 줄여라
선택지 비교
| 선택지 | 비용 | 해결 여부 |
|---|---|---|
| DB 인스턴스 업그레이드 (~$100/월) | 지속 비용 | 일시적 — 쿼리가 많다는 근본 원인은 그대로 |
| 앱단 캐싱 + 커넥션 풀 재배분 | 0원 | 근본 원인 해결 |
판단 근거
"CPU/메모리가 한가한데 돈 쓰는 건 낭비" 라는 엔지니어링 판단.
- 사양을 올리면
max_connections만 늘 뿐, 쿼리 수는 그대로. - 더 큰 DB에서도 같은 현상이 더 큰 규모로 반복될 뿐.
- 먼저 쿼리 수를 줄이고, 그래도 부족하면 그때 인프라.
Phase별 개선 스토리
Phase 0: 문제 식별
- 3,000 VU 부하테스트에서 503 발견
- Seat P99 6,887ms, Queue 503 40건, Seat 503 18건
- "DB 사양 문제일까?" → 아니었다
Phase 1 (1차): Seat BookingOptions API 선행 캐싱 (PoC)
- 가장 호출량이 많은
matchRepository.findByIdOrThrow먼저 Caffeine 캐싱 - P99 8초대 → 2초대 (약 75% 감소)
- 이 결과로 "캐싱 전략이 먹힌다" 검증 → 확대 적용의 근거
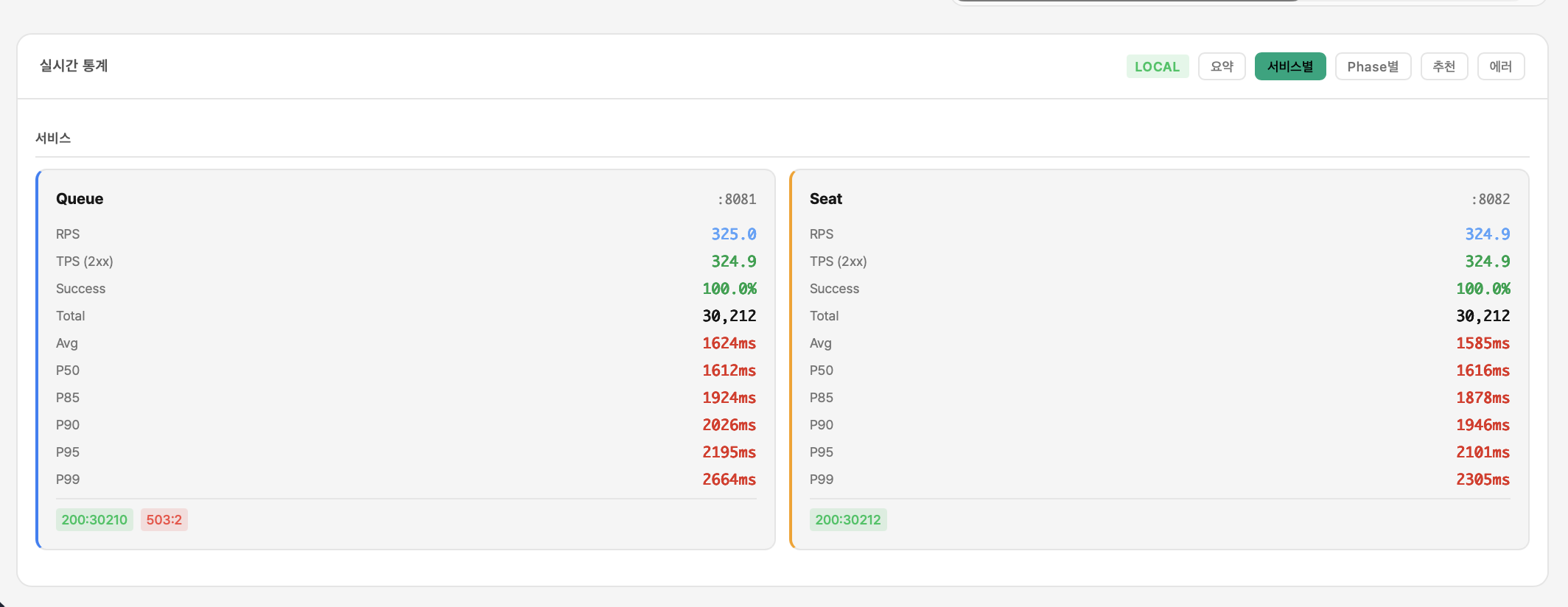
Phase 1 확대: 전면 적용
적용 범위
- Seat: Match 상세 + Section 전체 + 섹션별 Block (3종)
- Queue: 대기열 진입 시 Match 조회 (TTL 1m, saleStatus 반영 주기)
- Order-Core: 주문서 조회 시 Match (주문 생성 제외 — 영속성 컨텍스트 보존)
병행 조치
- 커넥션 풀 재배분 (seat/queue/auth 합계 DB 한도 내)
- Tomcat 스레드 200 → 400 (CPU 여유 활용)
Phase 2: Redis 분산 캐시
/auth/me,UserRepository, 온보딩 데이터는 사용자별 데이터- 로컬 캐시 부적합 → Redis 분산 캐시로 별도 작업
Phase 3~4: 인프라 튜닝 + 코드 핫픽스
- 응답 레벨 Redis 캐시 (seat-groups 5s, matches-list 30s)
- Queue OSIV OFF + Resilience4j + Lua 스크립트 통합
- 최종 Queue Flow P99 65ms
발표용 숫자 대시보드
| 항목 | 값 | 맥락 |
|---|---|---|
| DB CPU | 10% | 사양 문제 아님 입증 |
| DB Memory | 25% | 사양 문제 아님 입증 |
| DB max_connections | 250 | 실제 한계선 (db.t4g.medium) |
| Tomcat 스레드 peak | 735 | 자원 고갈의 외형적 증거 |
| Seat P99 (AS-IS) | 6,887ms | 개선 전 |
| Seat P99 (1차 PoC) | 2,000ms | 하나만 캐싱해도 75% 감소 |
| Seat P99 (TO-BE) | 65ms | 최종 98% 감소 |
| 503 발생률 (AS-IS) | 1.7% (Queue) | 개선 전 |
| 503 발생률 (TO-BE) | 0% | 완전 제거 |
| 업그레이드 비용 (안 쓴 돈) | ~$100/월 | "최적화로 아낀 돈" |
반박 대응 Q&A
Q1. "그래도 DB 올리면 안전하지 않나?"
A. 맞지만 근본 해결이 아님. 쿼리 수가 그대로면 더 큰 DB에서도 같은 현상이 더 큰 규모로 반복. 게다가 CPU/메모리 사용률이 10%/25%인데 올리면 자원 낭비. "병목을 옮기는 것과 제거하는 것의 차이".
Q2. "캐시 일관성은 괜찮은가?"
A. 캐싱 대상을 고른 기준:
- Match, Stadium, Section, Block → 배포 단위로만 변경되는 준불변 데이터
- TTL 기반 eventual consistency 허용 가능 (Match 10분, Section 1시간, Queue용 Match 1분)
- 사용자별 변동 데이터(User, Onboarding)는 Phase 1에서 제외 → Redis 분산 캐시(Phase 2)로 별도 처리
Q3. "왜 Caffeine? Redis 아니고?"
A. 정합성 요구가 낮고 read-heavy/write-rare 한 데이터에는 로컬 캐시가 최적:
- 네트워크 홉 제거 → sub-ms 응답
- Redis도 0.5~2ms 드는데 그만큼도 아낌
- 인프라 의존성 추가 없음
- 실시간 정합성 필요한 데이터만 Redis로 분리 (Phase 2~3)
Q4. "5000 VU는 가능?"
A. 현 인프라로는 불가능 — 정직하게 한계 인정.
db.t4g.mediummax_connections 250 절대 한계- 5000 VU는
db.m6g.large(max ~900) 이상 필요 - "현 인프라로 1000 VU P95 < 1s 목표 달성"이 본 개선의 현실적 스코프
- 폴더 20 결과(좌석 Hold 성공률 83.6%)에서 확인: 1000 VU가 우리 인프라의 정직한 상한
시각화 자료
슬라이드 1: Before/After 흐름
Before: [사용자] → [Envoy] → [Pod: 스레드 대기] → [HikariCP 대기] → [DB 한가] ❌ 503
After: [사용자] → [Envoy] → [Pod: 캐시 hit] → 즉시 응답 ✅슬라이드 2: 인과관계 도식
쿼리 많음 → 커넥션 짧게 자주 잡음 → 풀 포화 → Tomcat 스레드 대기 → accept-queue 포화 → 503
↑
여기를 끊는다 (Caffeine 캐시)슬라이드 3: 숫자 대시보드
- P99: 6,887ms → 65ms (-99%)
- 503: 1.7% → 0%
- DB CPU: 10% (사양 문제 아님)
- 절감 비용: ~$100/월
스토리 톤
- "돈 쓰면 되는 문제였는데 엔지니어링으로 해결했다" 서사
- "현상만 보고 사양을 올리는 게 아니라, 원인을 파고든다" 관점
- 겸손한 결론: "5000 VU는 여전히 DB 업그레이드가 필요하다" — 과도한 자신감 대신 한계 인정으로 신뢰 확보
- 팀 커뮤니케이션 언급 (클라우드 그룹장 진단 + 백엔드 조치) — 협업 스토리