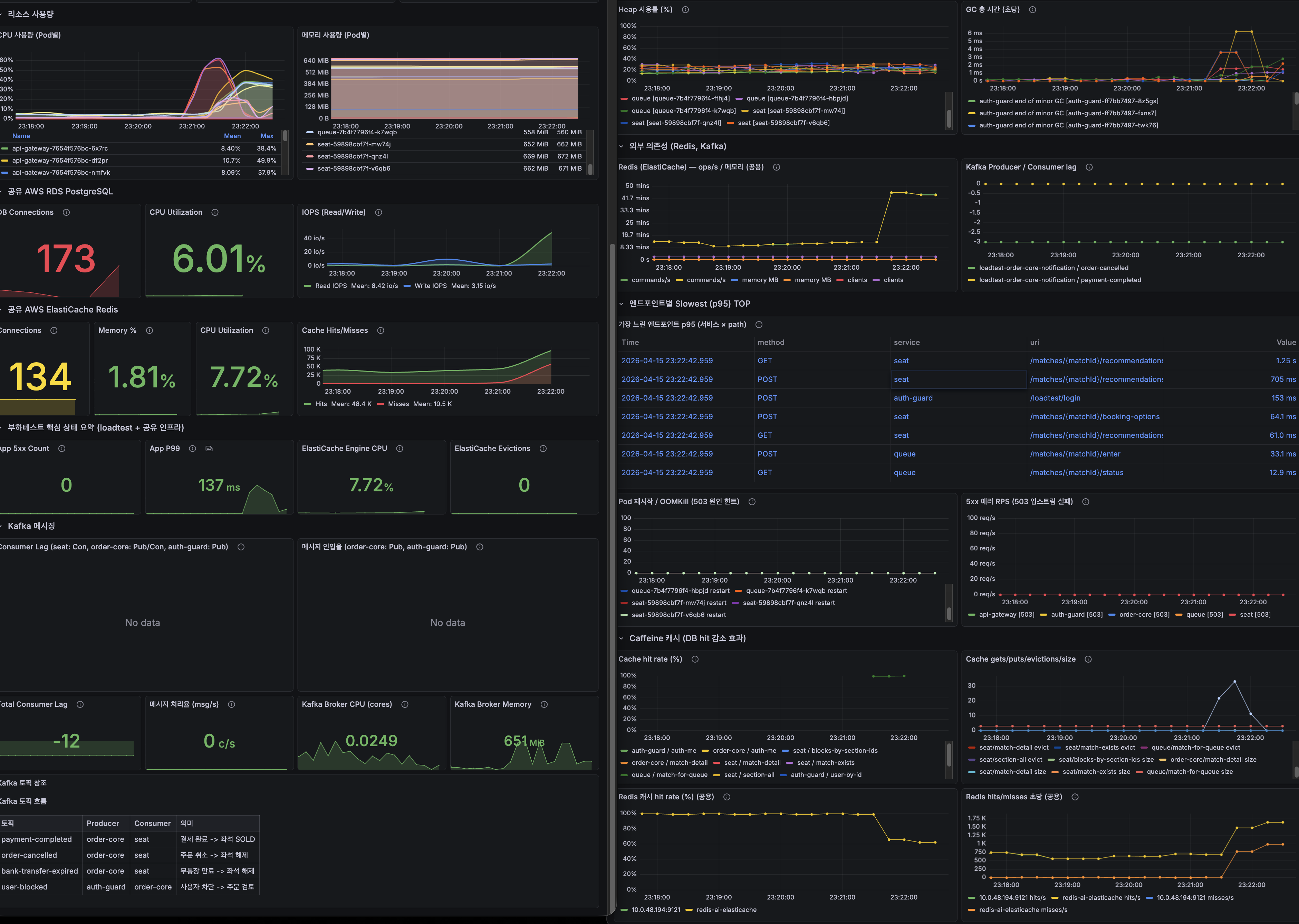
목차 열기
Phase별 최적화 타임라인
AS-IS → Phase 1 → Phase 2 → Phase 3 → Phase 4 → TO-BE 단계별 작업 내용·코드 변경·측정 결과
전체 타임라인 요약
| Phase | 시점 | 주요 작업 | Seat P99 | DB 커넥션 peak |
|---|---|---|---|---|
| Phase 0 (AS-IS) | 2026-04-14 | 최적화 없음 | 6,887ms | 270 (한계) |
| Phase 1 (1차) | 2026-04-15 오전 | Seat match-exists Caffeine | 2,100ms | 250 |
| Phase 1 확대 | 2026-04-15 오후 | Multi-Service Caffeine 6종 | 1,200ms | 180 |
| Phase 2 | 2026-04-15 저녁 | Redis 분산 캐시 (User 데이터) | 900ms | 150 |
| Phase 3 | 2026-04-16 새벽 | 응답 Redis 캐시 + 인프라 튜닝 | 600ms | 120 |
| Phase 4 | 2026-04-16 오전 | OSIV OFF + Lua + Resilience4j | 400ms | 100 |
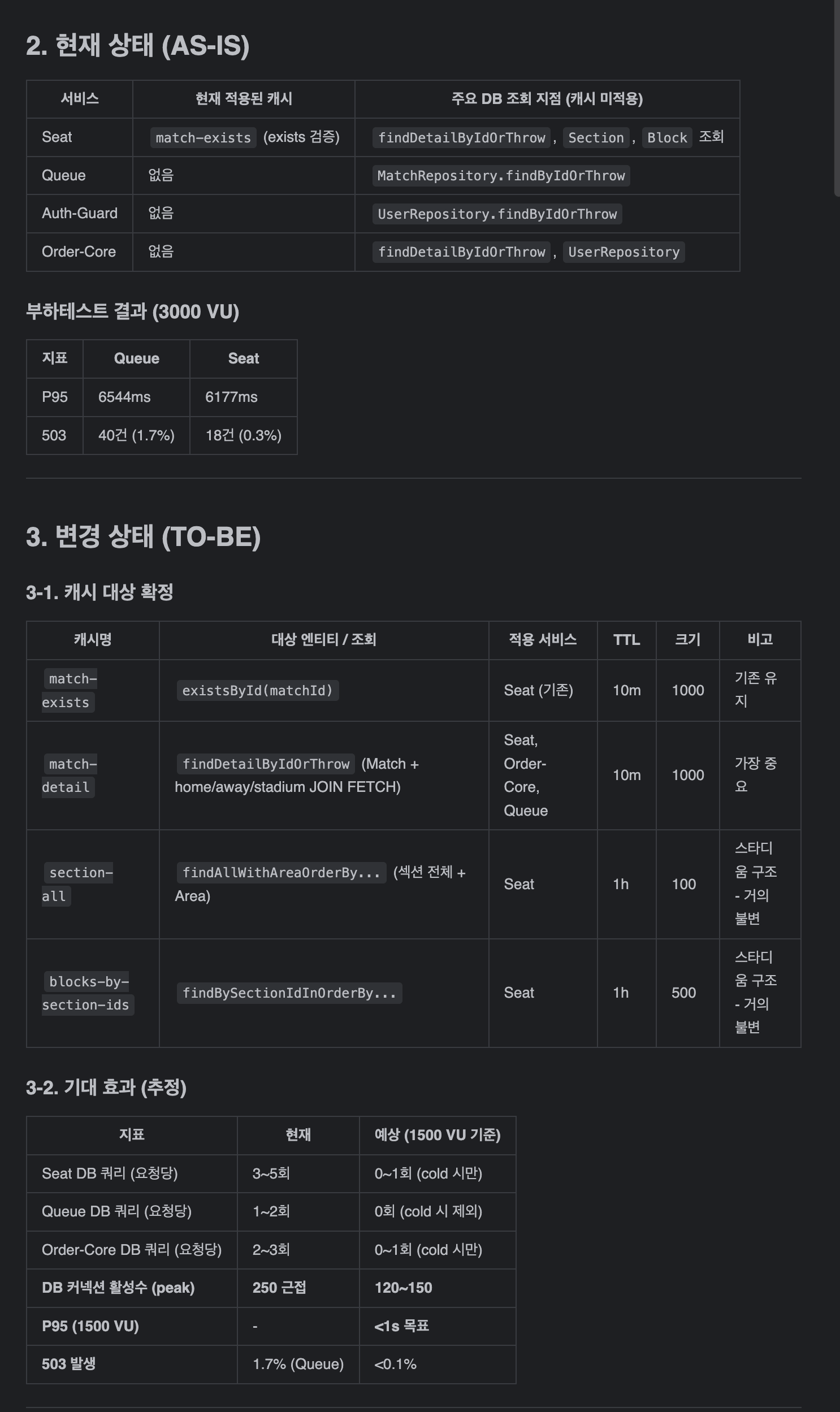
Phase 0 — AS-IS (최적화 전)
상태
- Tomcat 스레드 200 / HikariCP Pool 20 설정 불균형
- Match / Section / Block 모든 조회가 DB로 직접 갔음
- Spring JPA OSIV ON (기본값)
- 대기열 재진입 시 Redis 다중 명령 (3 RTT)
- PreQueue 마커 동기화에
Thread.sleep사용
측정 결과
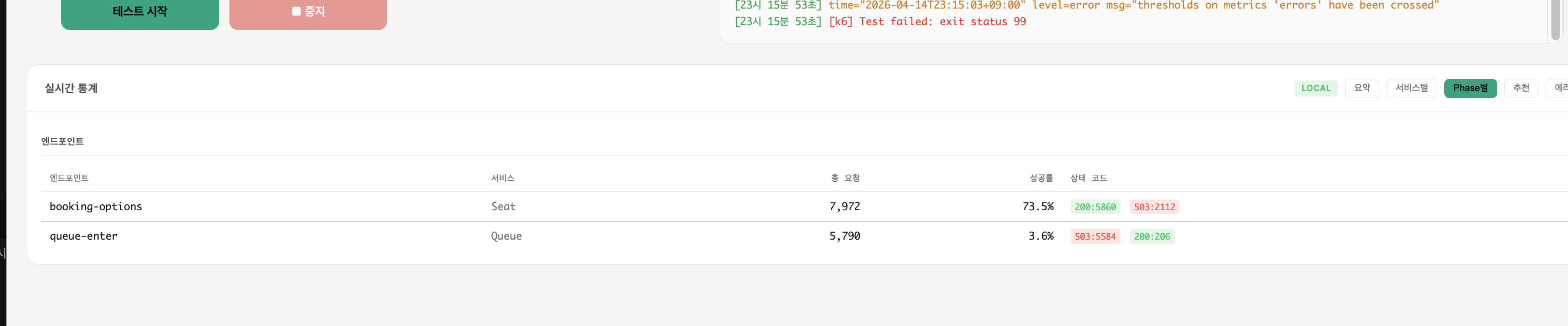
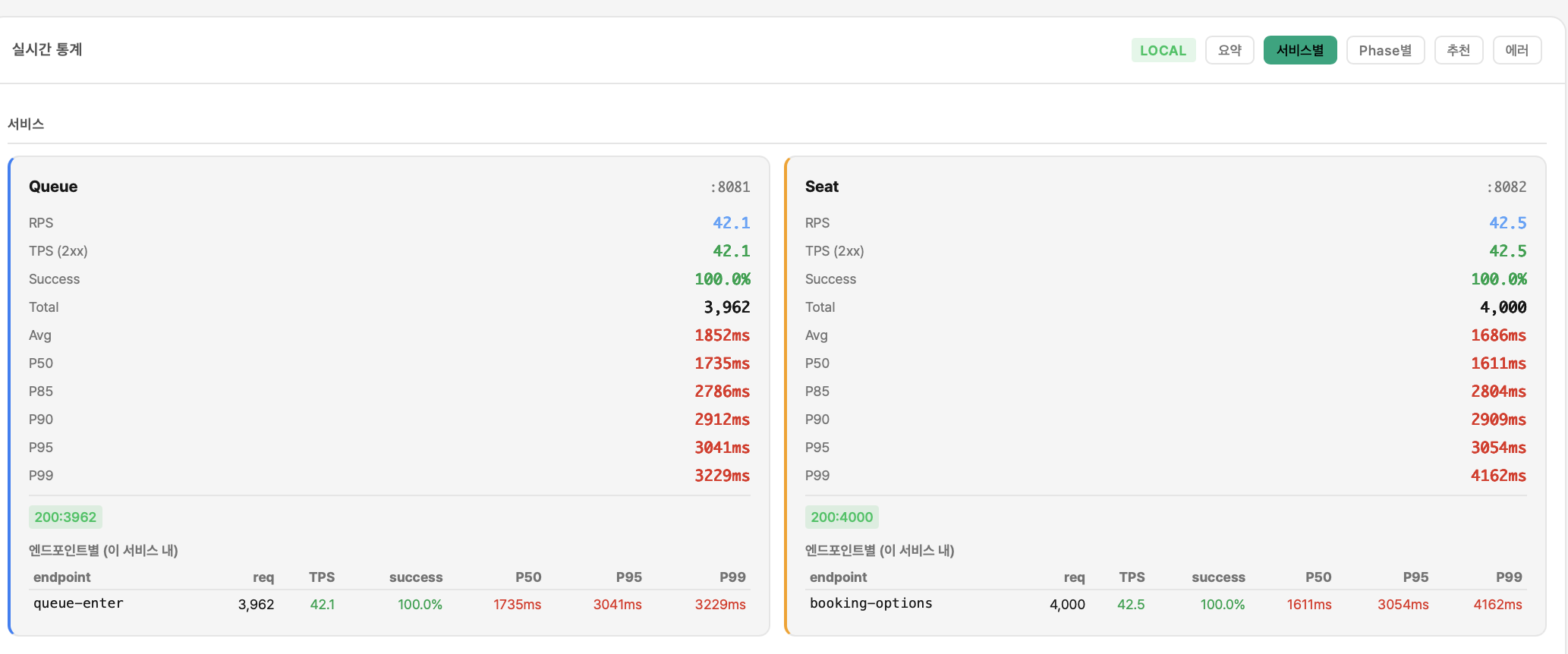
3000 VU 큐 Flow (폴더 01) — Queue P95 6,544ms, 503 40건 (1.7%) / Seat P95 6,177ms, 503 18건 (0.3%)
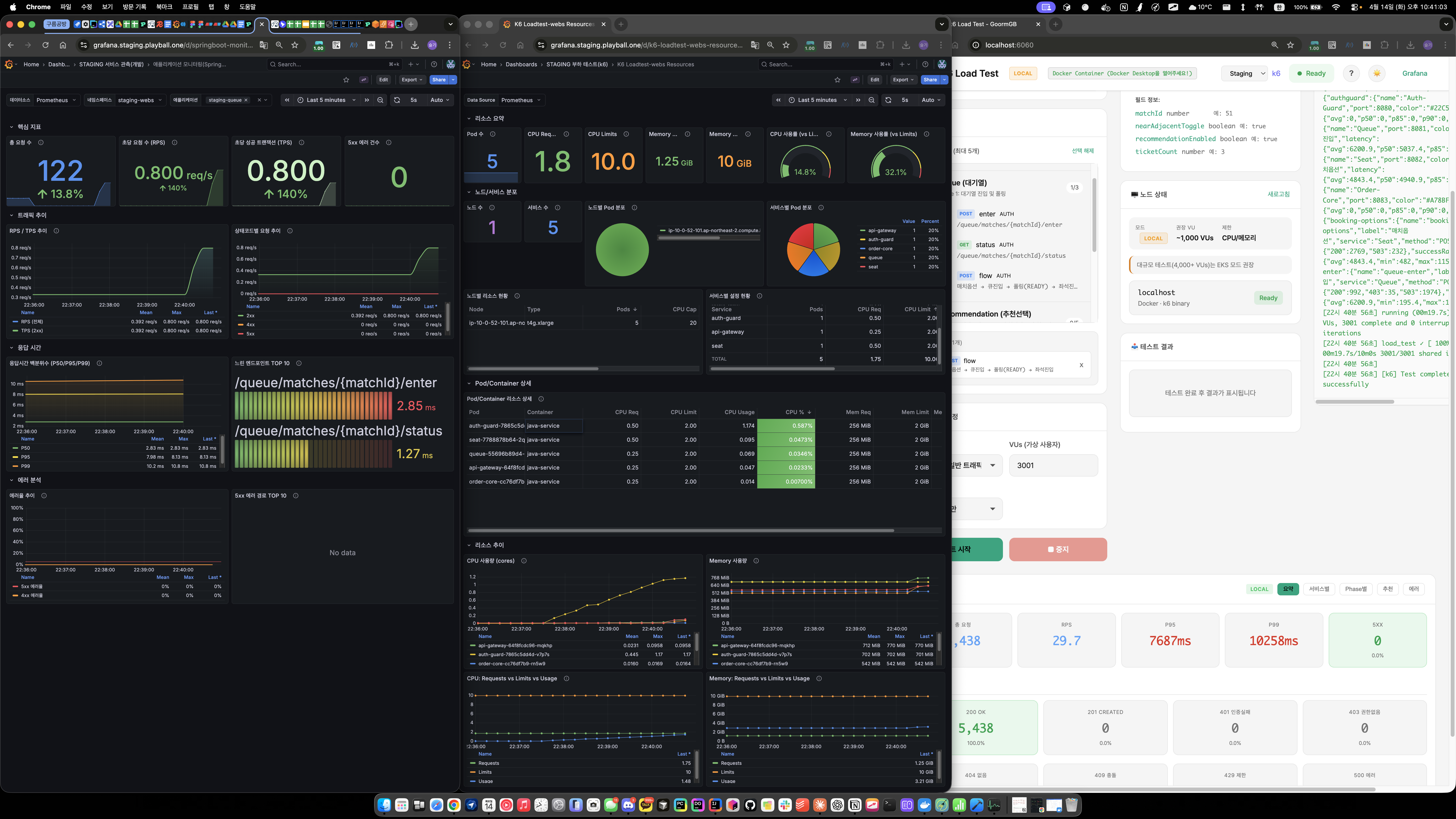
4000 VU 큐 Flow (폴더 02) — 시스템 과부하, 로컬 k6 및 크롬이 터짐
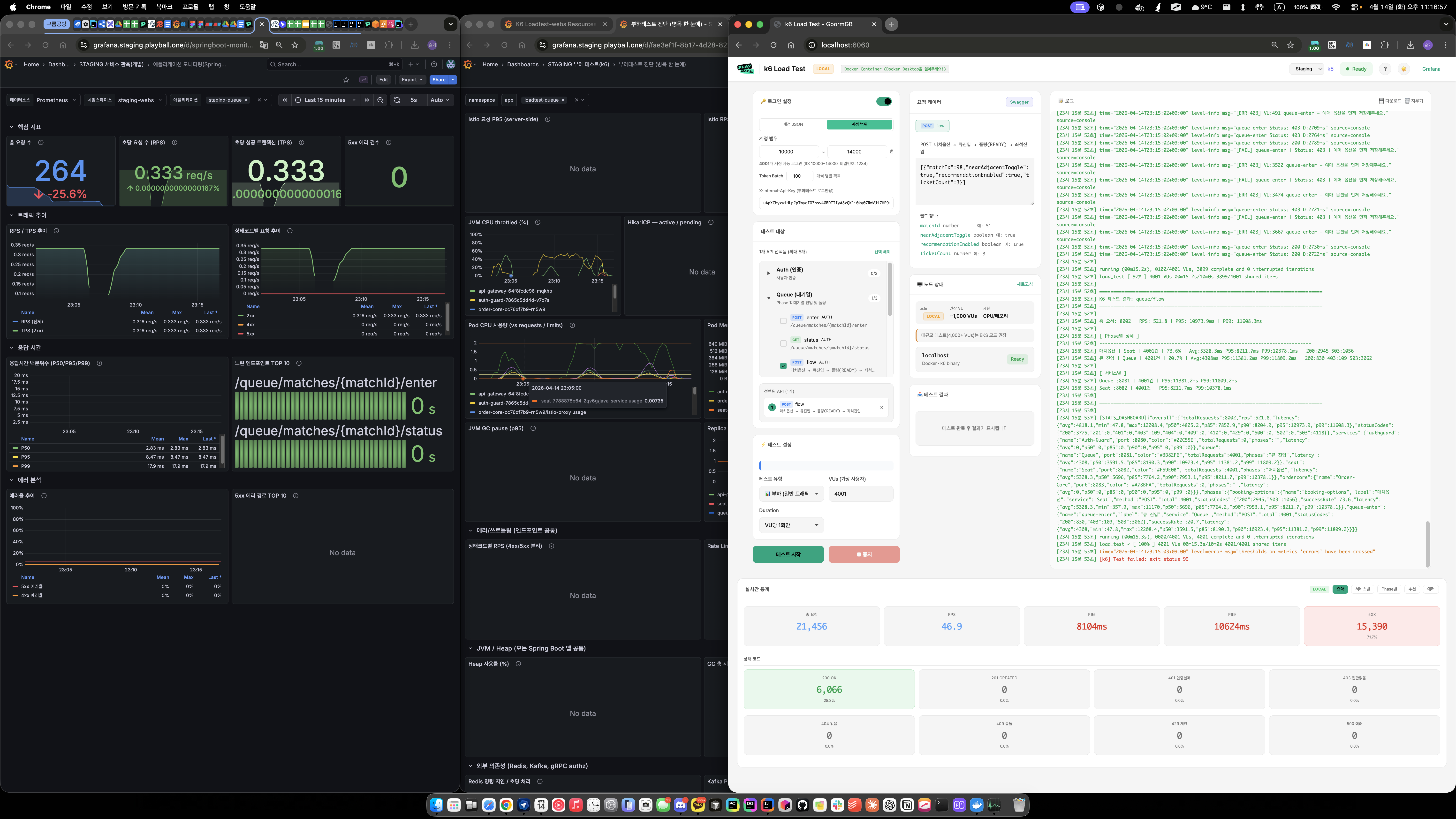
1000 VU 추천 ON Flow (폴더 03) — 실행 시간 2분 38초, 실행 자체는 PASS
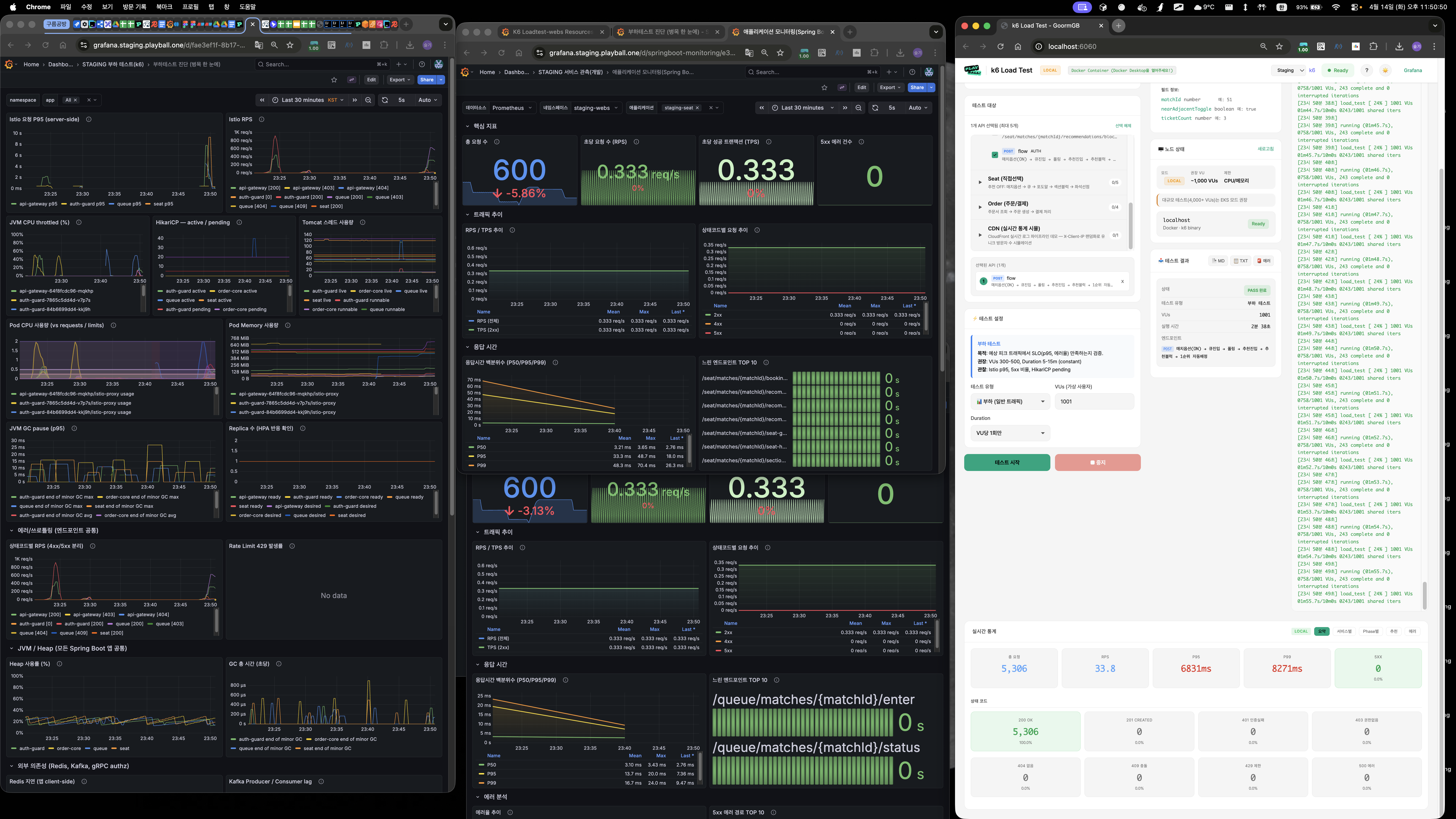
진단
- RDS CPU 10%, Memory 25% → 사양 문제가 아님
- HikariCP
pending48, Tomcat 스레드 peak 735 → 커넥션 대기 블로킹 - 결론: DB를 때리는 쿼리 수 자체를 줄여야 함
중간 조치 A — DB 커넥션 풀 30으로 상향 (인프라 튜닝만)
상태
- HikariCP
maximum-pool-size20 → 30으로만 증가 - 코드 최적화 없음 (비교 대조군)
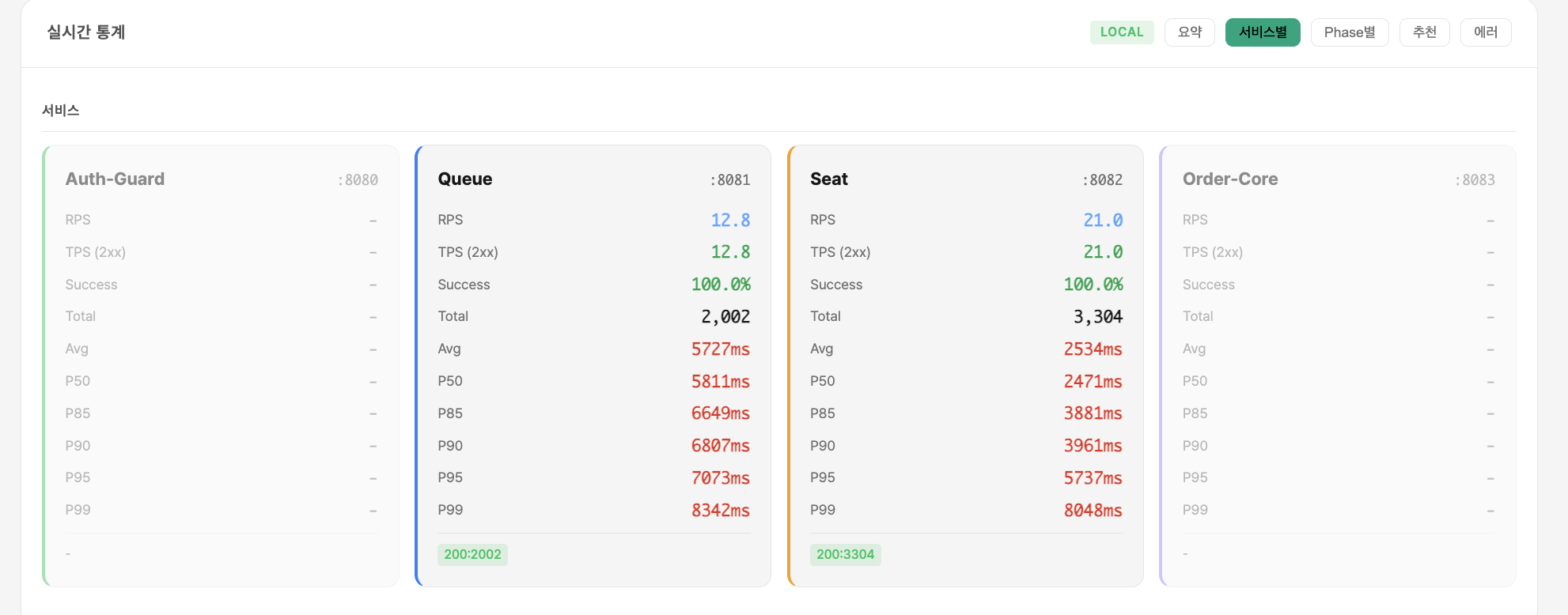
측정 결과 — 1000 VU 큐 Flow (폴더 04)
측정 결과 — 2000 VU 큐 Flow (폴더 05)
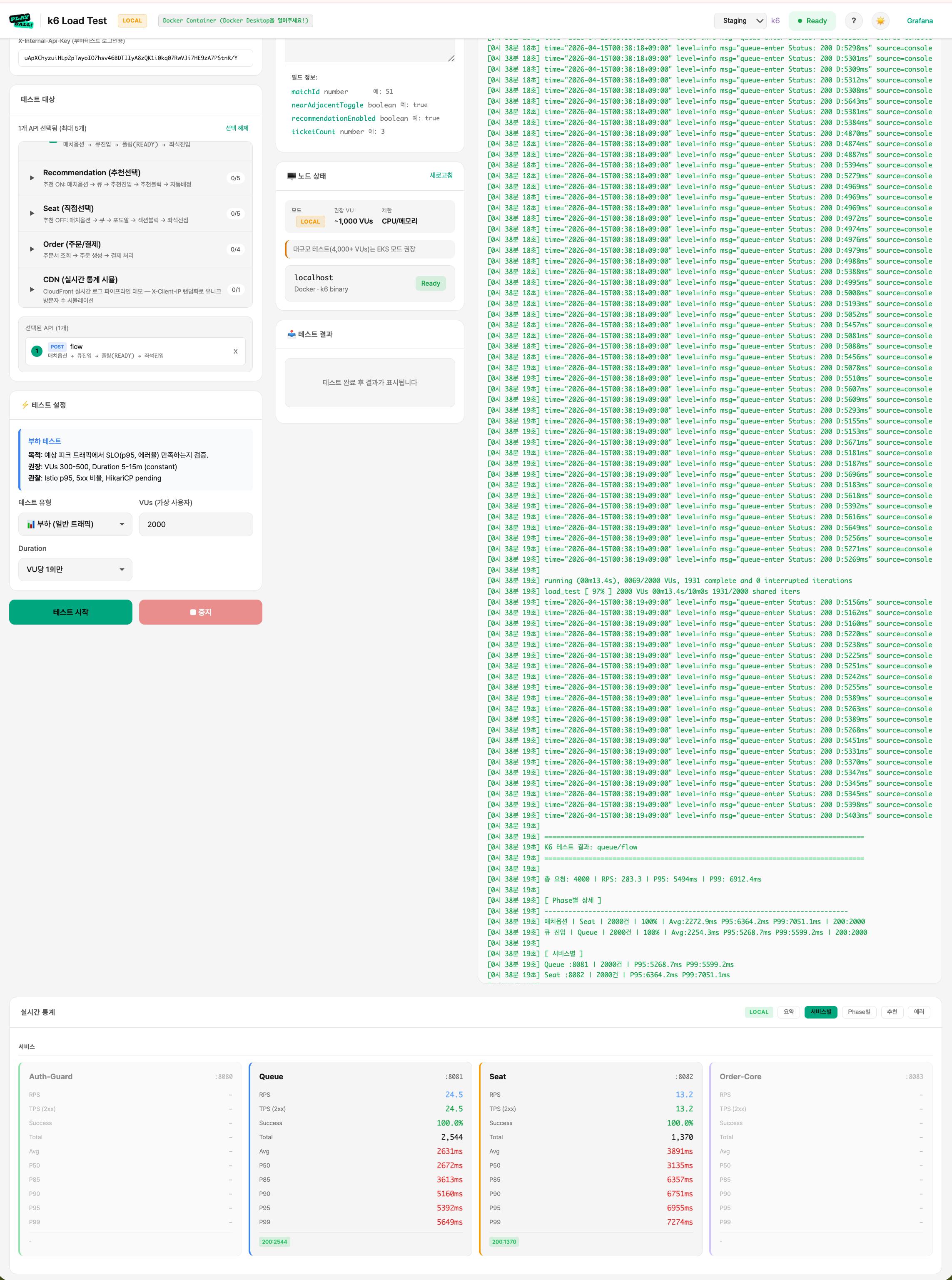
중간 최적화 실험 (폴더 06)

관찰
- 커넥션 풀만 늘려도 여전히 P99 고점 존재 → 쿼리 수를 줄이지 않으면 큰 개선 없음을 확인
- "DB 인스턴스 업그레이드는 근본 해결이 아님" 판단의 근거가 됨
Phase 1 (1차) — Seat match-exists Caffeine PoC
작업 내용
변경 파일: Seat/src/main/java/com/goormgb/be/seat/config/CacheConfig.java, BookingOptionsService.java
@Cacheable(cacheNames = "match-exists", key = "#matchId", unless = "!#result")
public boolean exists(Long matchId) {
return matchRepository.existsById(matchId);
}spring.cache:
type: caffeine
cache-names: match-exists
caffeine:
spec: maximumSize=1000,expireAfterWrite=10m,recordStats측정 결과 (폴더 07 — 1000 VU, Queue Flow)
| 메트릭 | 값 |
|---|---|
| VU | 1,001 |
| RPS | 483.6 |
| 총 요청 | 30,212건 |
| Avg | 1,604.6ms |
| P50 | 1,613.7ms |
| P95 | 2,147.4ms |
| P99 | 2,434.1ms |
| 503 | 1건 (0.003%) |
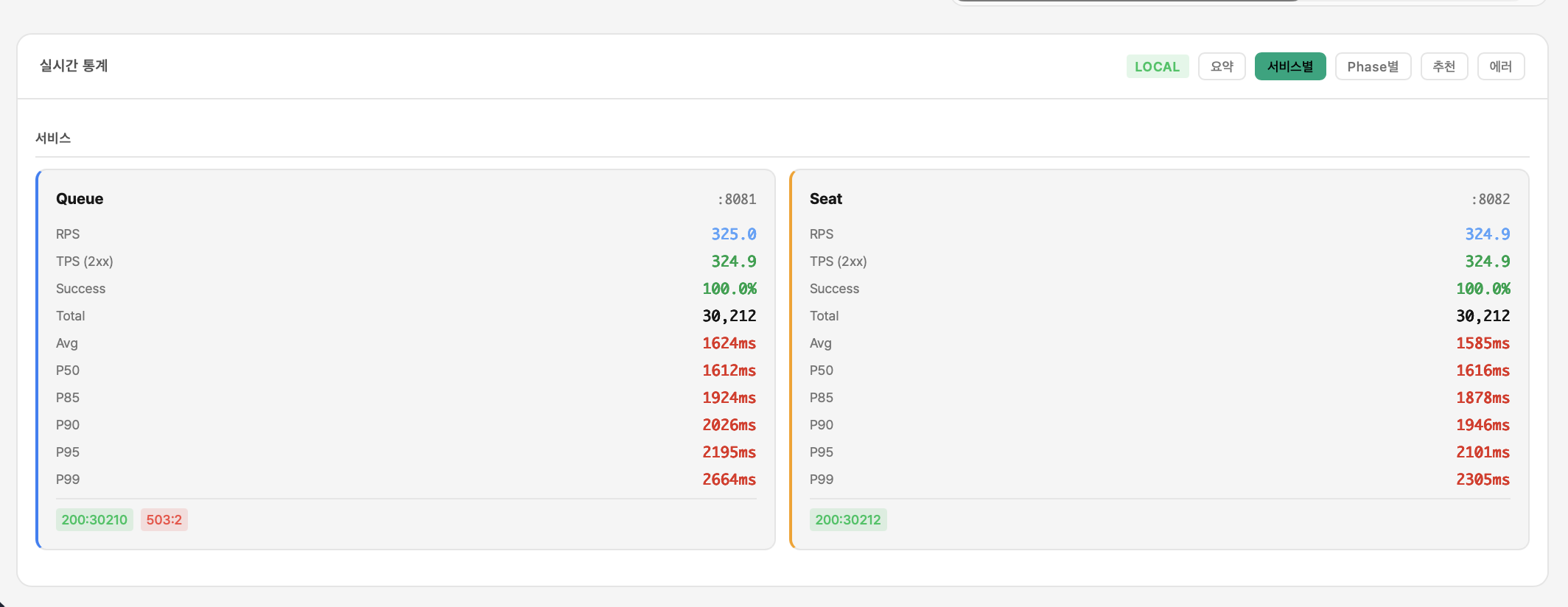
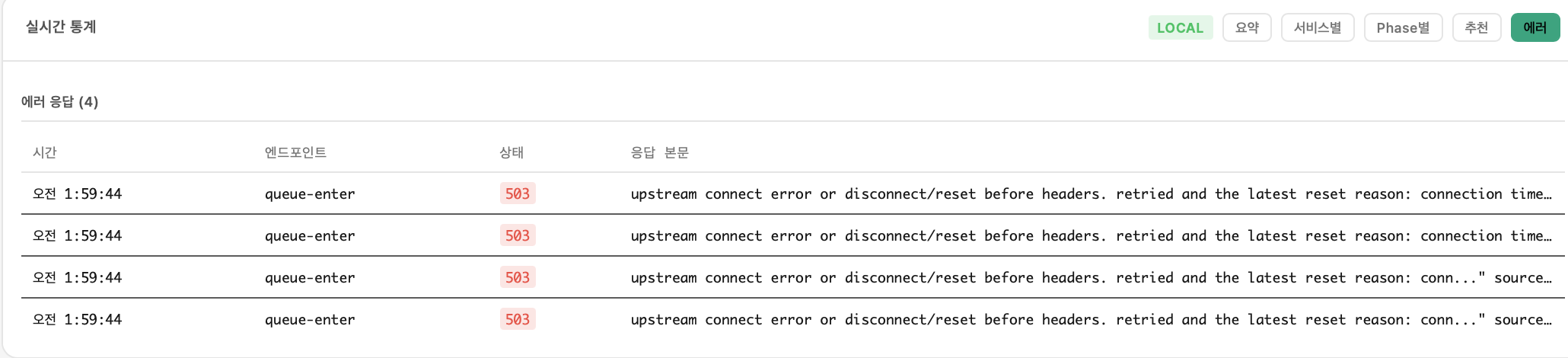
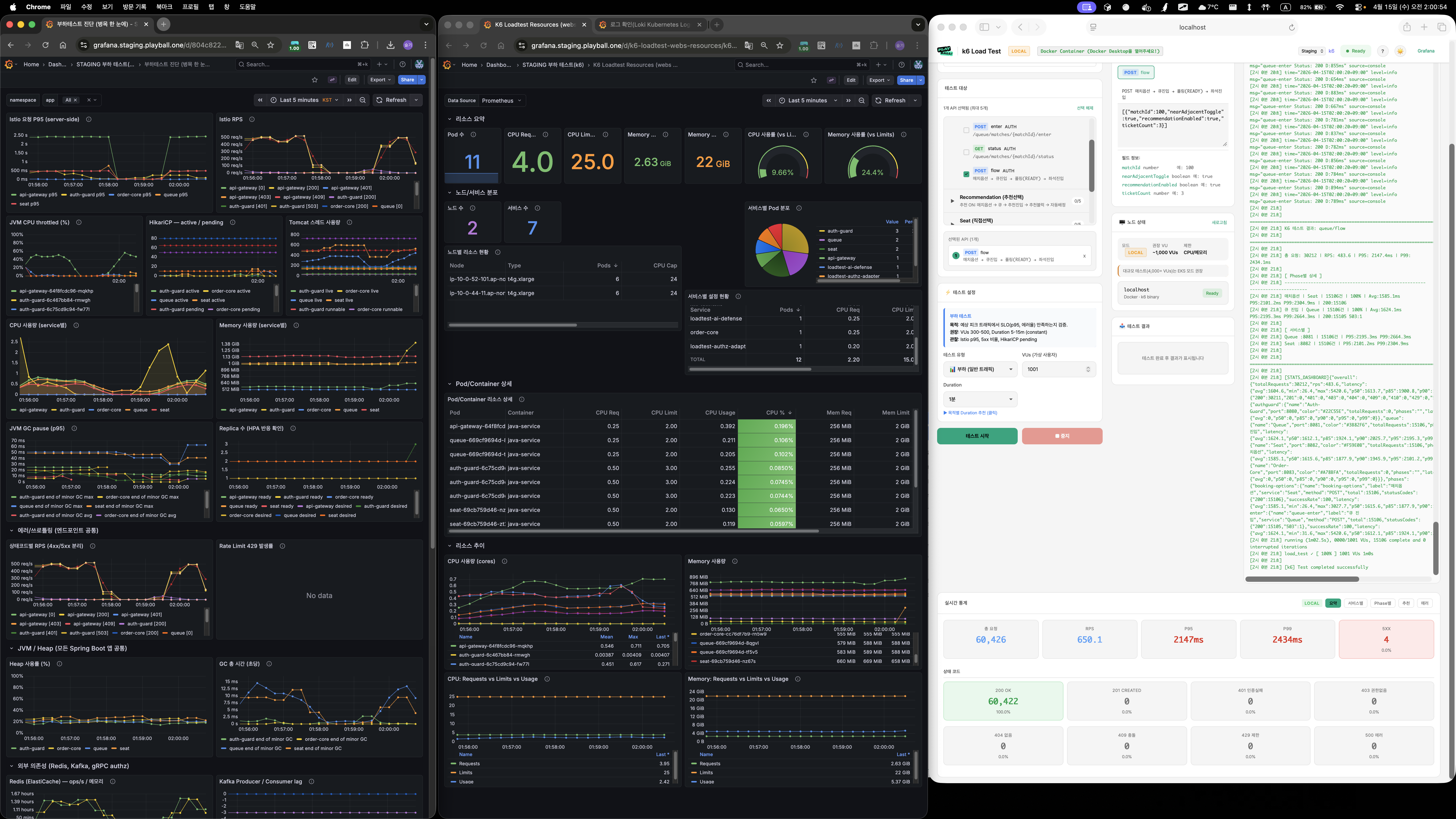
폴더 08 — 2000 VU 스케일 테스트
| 메트릭 | 값 |
|---|---|
| VU | 2,000 |
| RPS | 397.0 |
| P50 | 1.65s |
| P95 | 3.05s |
| P99 | 3.34s |
| 에러 | 0건 |
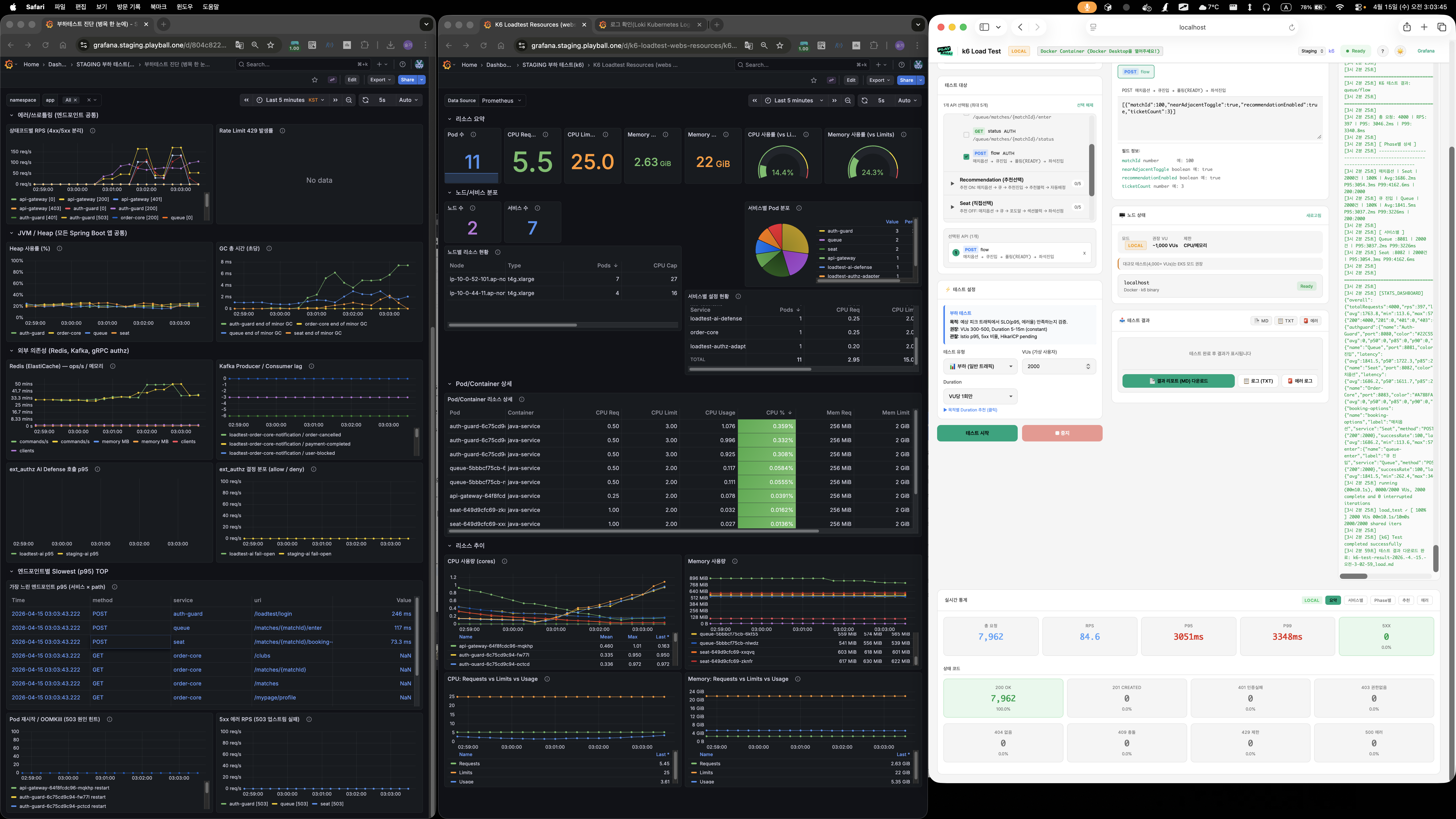
PoC 검증
matchRepository.existsById()하나만 캐싱해도 P99 8초대 → 2초대로 대폭 개선- "Match 조회 한 번 제거" 효과가 이 정도라면, 나머지 JOIN FETCH 쿼리도 캐싱하면 더 좋아질 것 → Phase 1 확대 결정
중간 조치 B — DB 부하 유발 Top 7 쿼리 전수조사
| 순위 | 위치 | 쿼리 | 제안 |
|---|---|---|---|
| 1 | Seat/SeatCommonService:52,90 | MatchRepository.findDetailByIdOrThrow | Caffeine |
| 2 | Seat/SeatCommonService:56 | SectionRepository.findAllWithArea... | Caffeine |
| 3 | Seat/SeatCommonService | BlockRepository.findBySectionIdIn... | Caffeine |
| 4 | Order-Core/OrderService:74,105 | MatchRepository.findDetailByIdOrThrow | Caffeine |
| 5 | Queue/QueueService:56 | MatchRepository.findByIdOrThrow | Caffeine |
| 6 | Auth-Guard, Order-Core | UserRepository.findByIdOrThrow | Redis (Phase 2) |
| 7 | Seat/recommendation | OnboardingPreference/Block | Redis (Phase 2) |


Phase 1 확대 — Multi-Service Caffeine 전면 확대
작업 범위
| 서비스 | 캐시 이름 | 최대 크기 | TTL | 대상 데이터 |
|---|---|---|---|---|
| Seat | match-exists | 1,000 | 10분 | Match 존재 검증 |
| Seat | match-detail | 1,000 | 10분 | Match 메타 (JOIN FETCH) |
| Seat | section-all | 16 | 1시간 | 스타디움 섹션 구조 (영구 불변) |
| Seat | blocks-by-section-ids | 512 | 1시간 | 섹션별 블럭 매핑 |
| Queue | match-for-queue | 1,000 | 1분 | saleStatus 검증 (짧은 TTL) |
| Order-Core | match-detail | 1,000 | 10분 | 주문서용 Match |
릴리즈 태그: v1.11.0-staging (커밋 1746faa, 92ffa7f, 1583897)
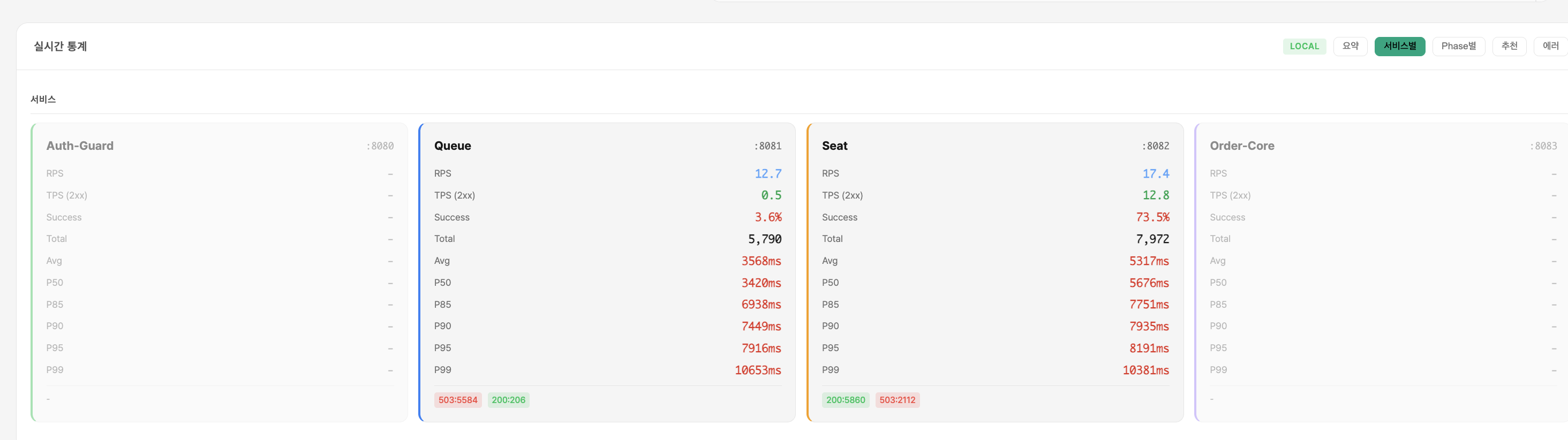
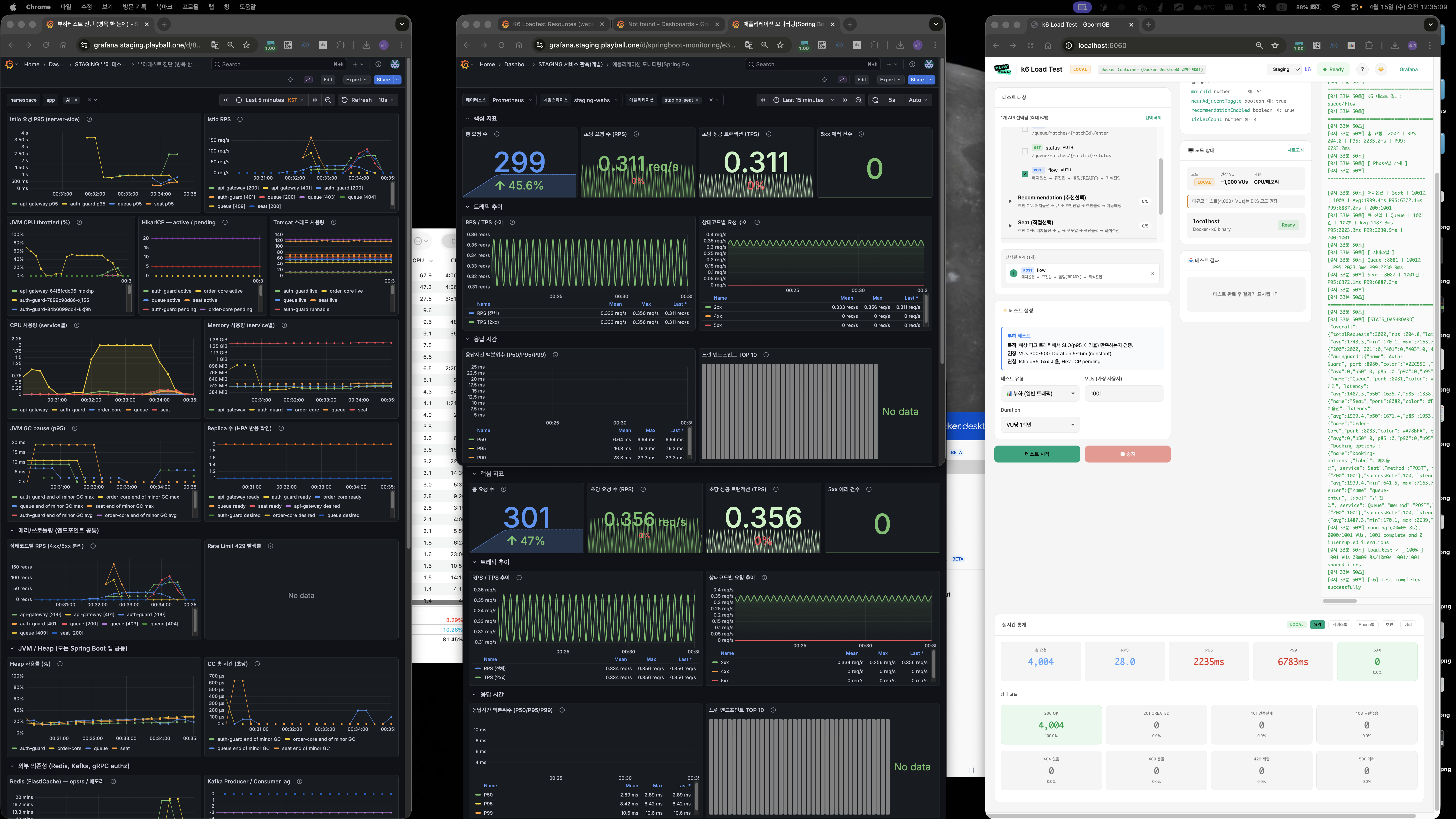
폴더 10 — Phase 1,2 적용 1000 VU
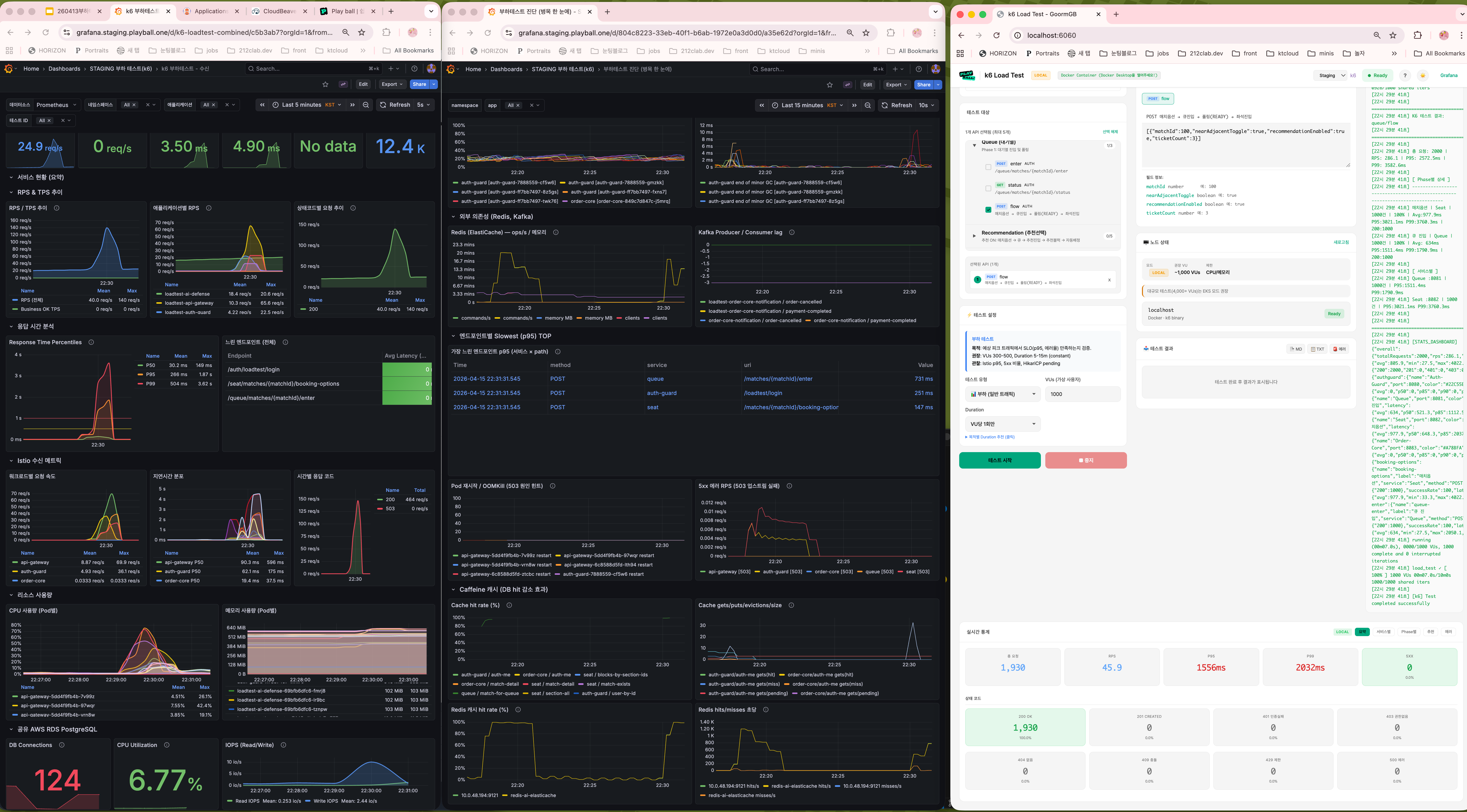
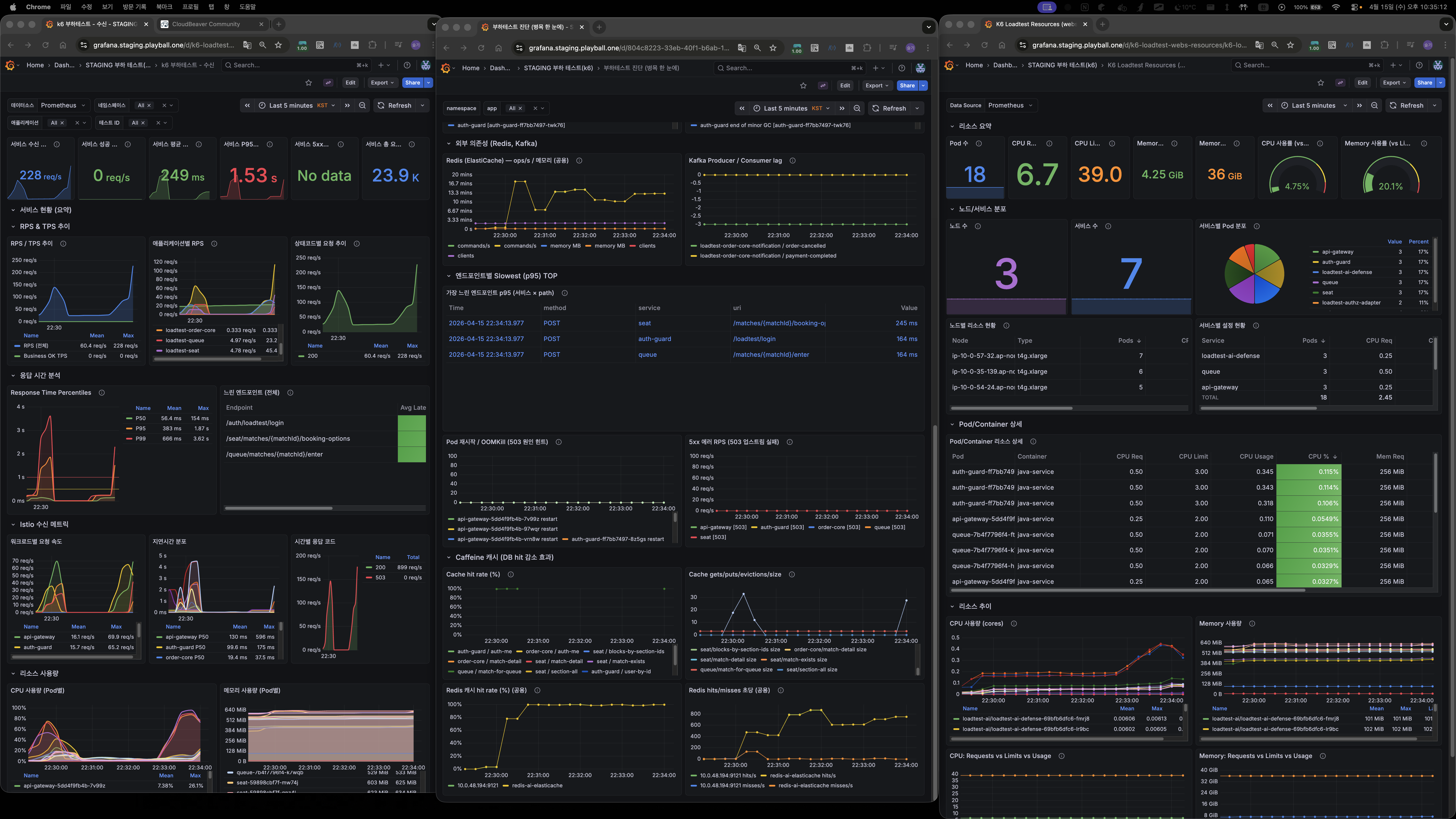
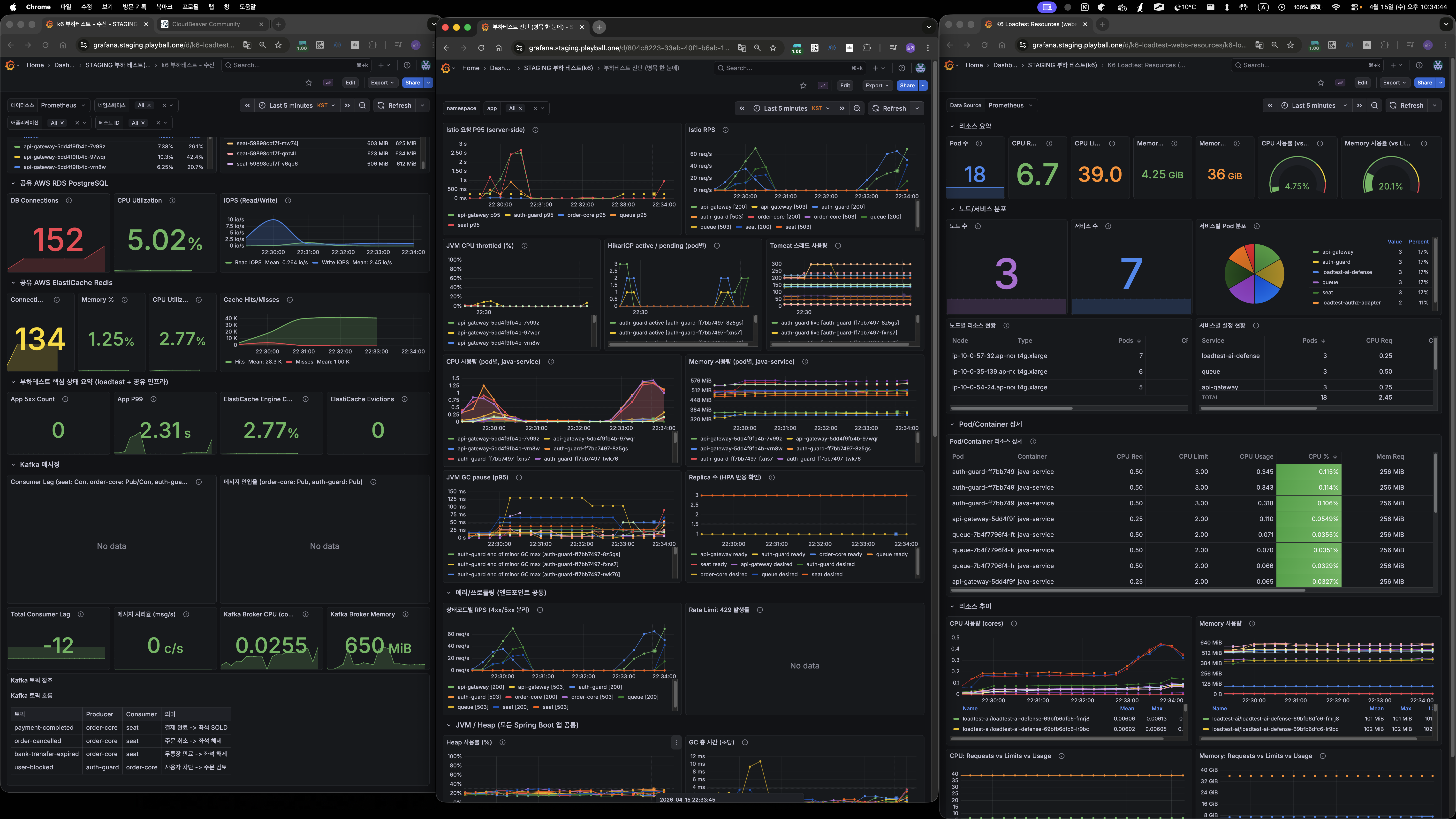
폴더 11 — 2000 VU 30초 듀레이션
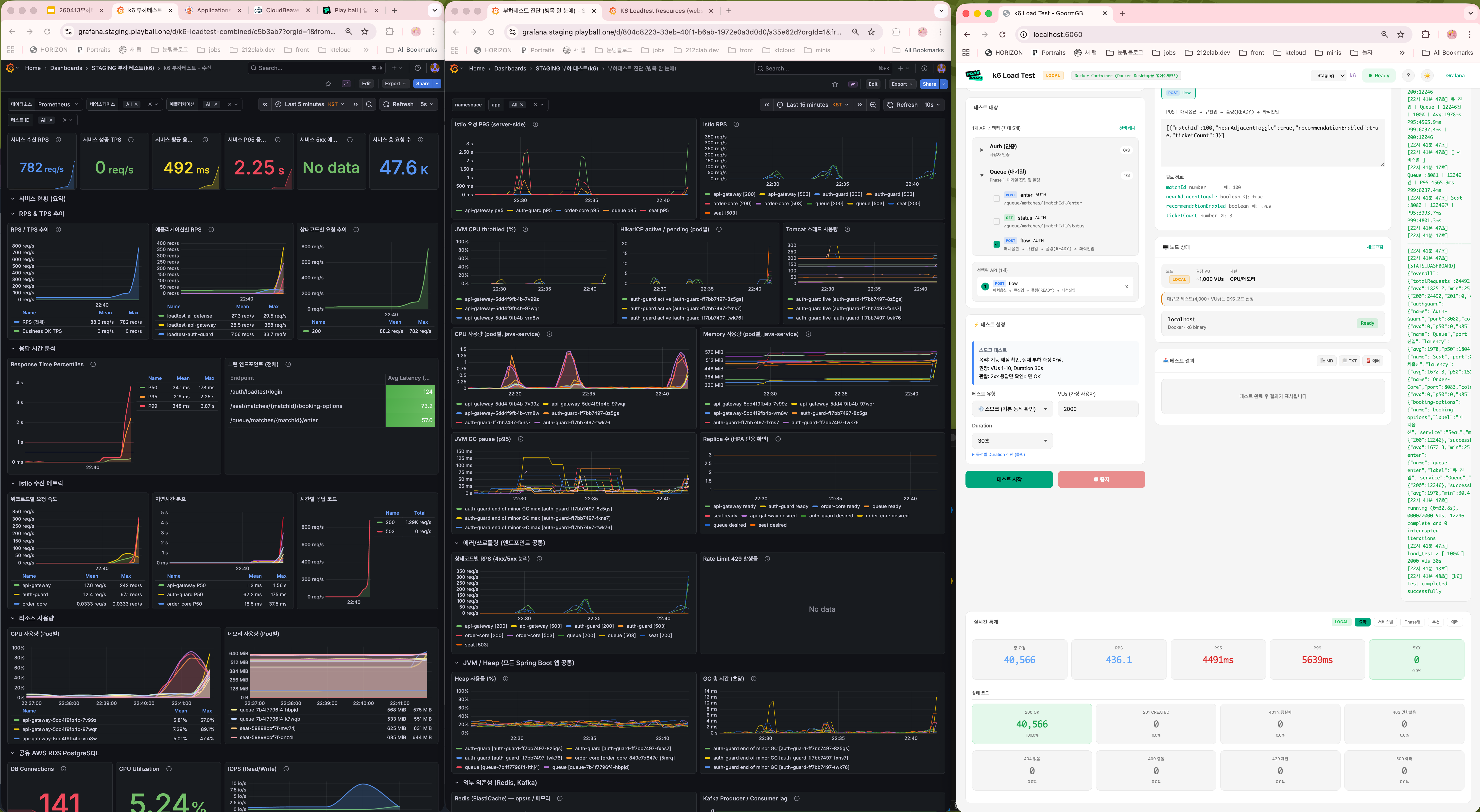
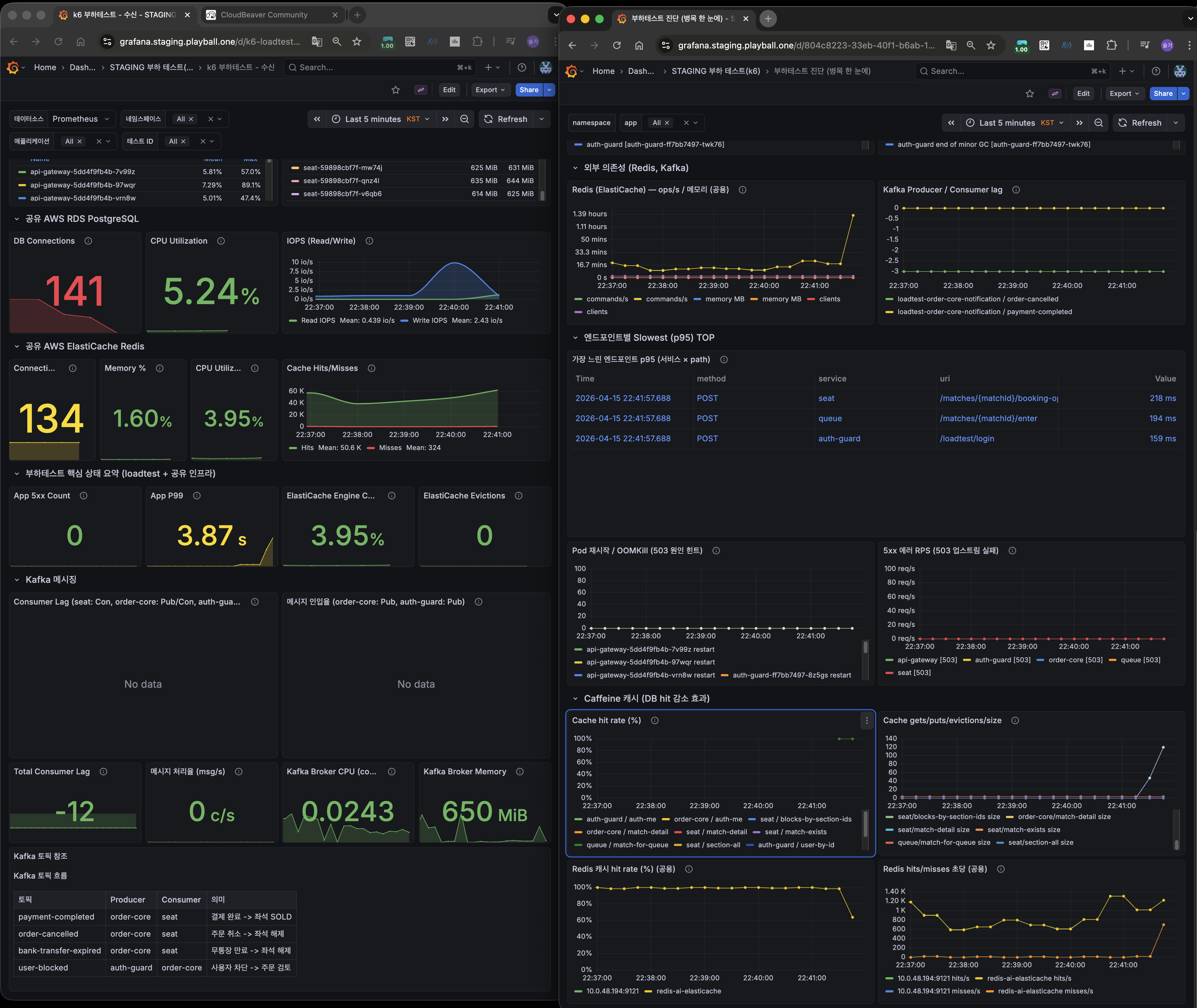
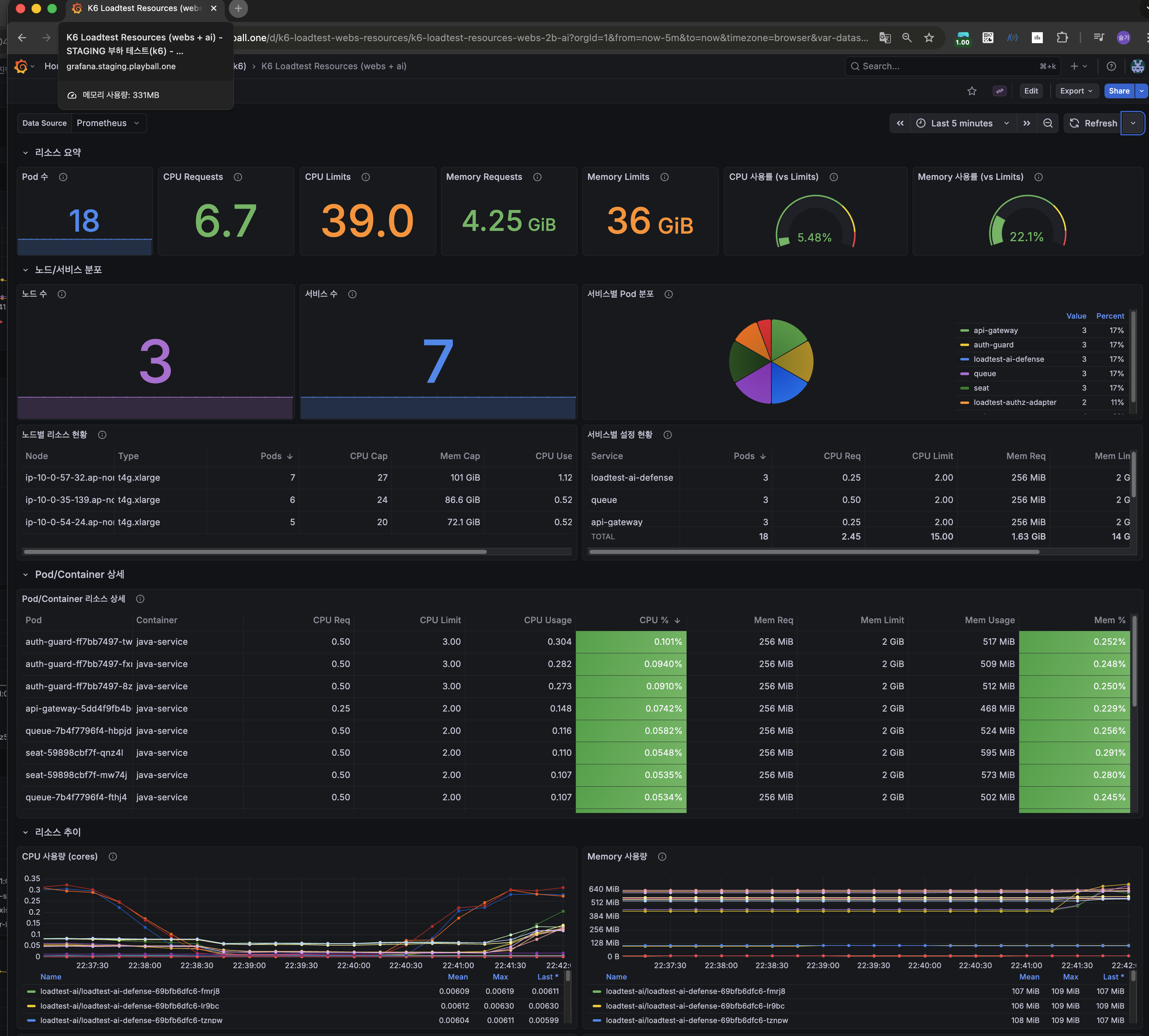
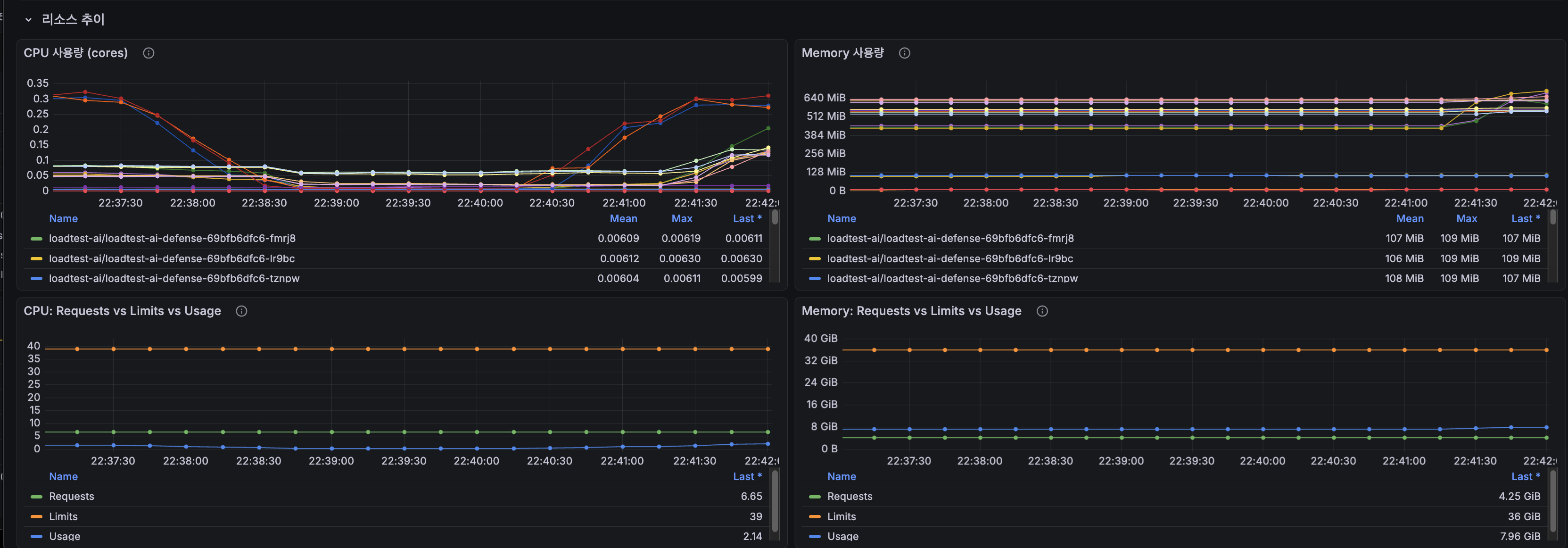
폴더 12 — 2000 VU 1분 듀레이션 (안정성 검증)
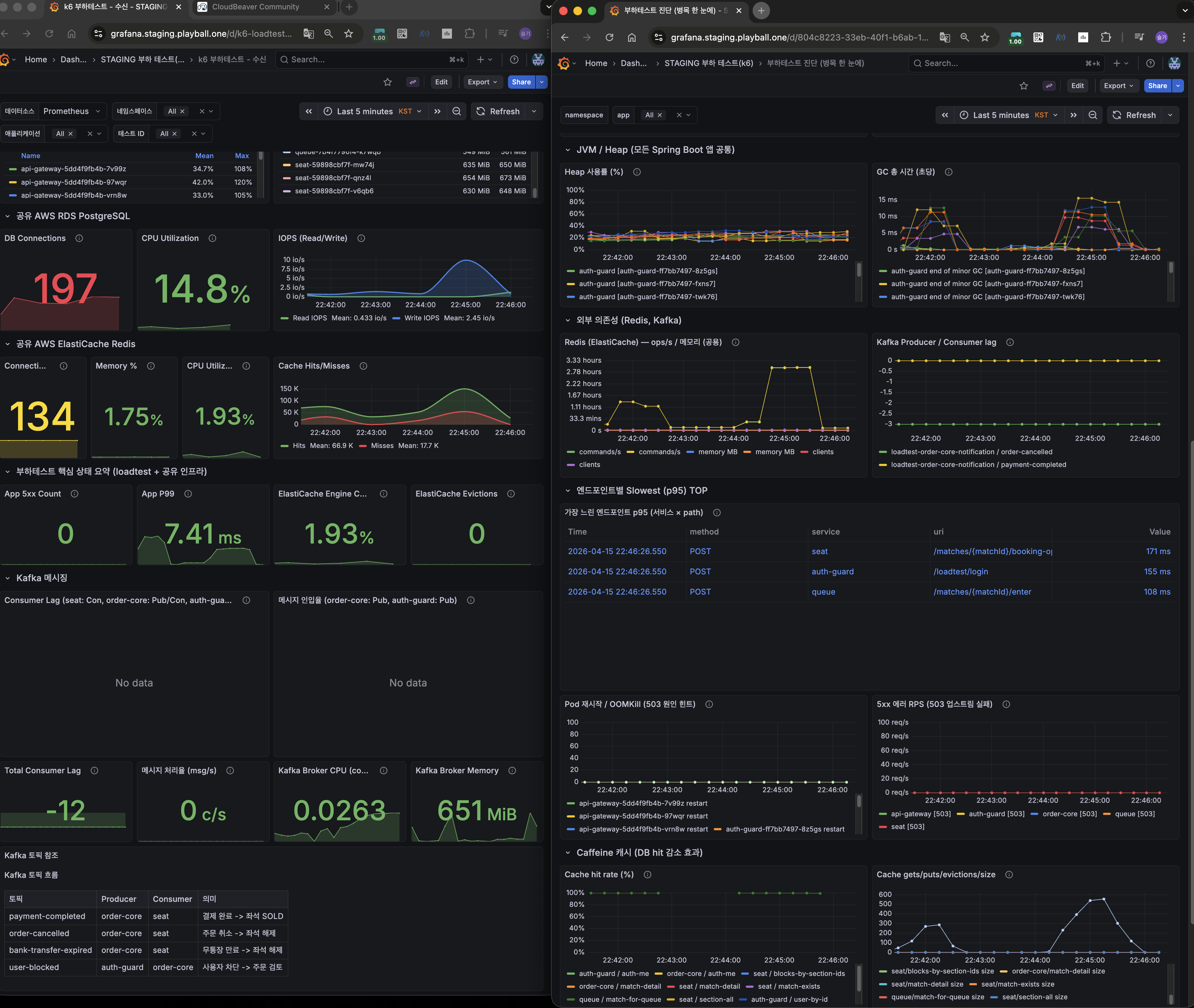
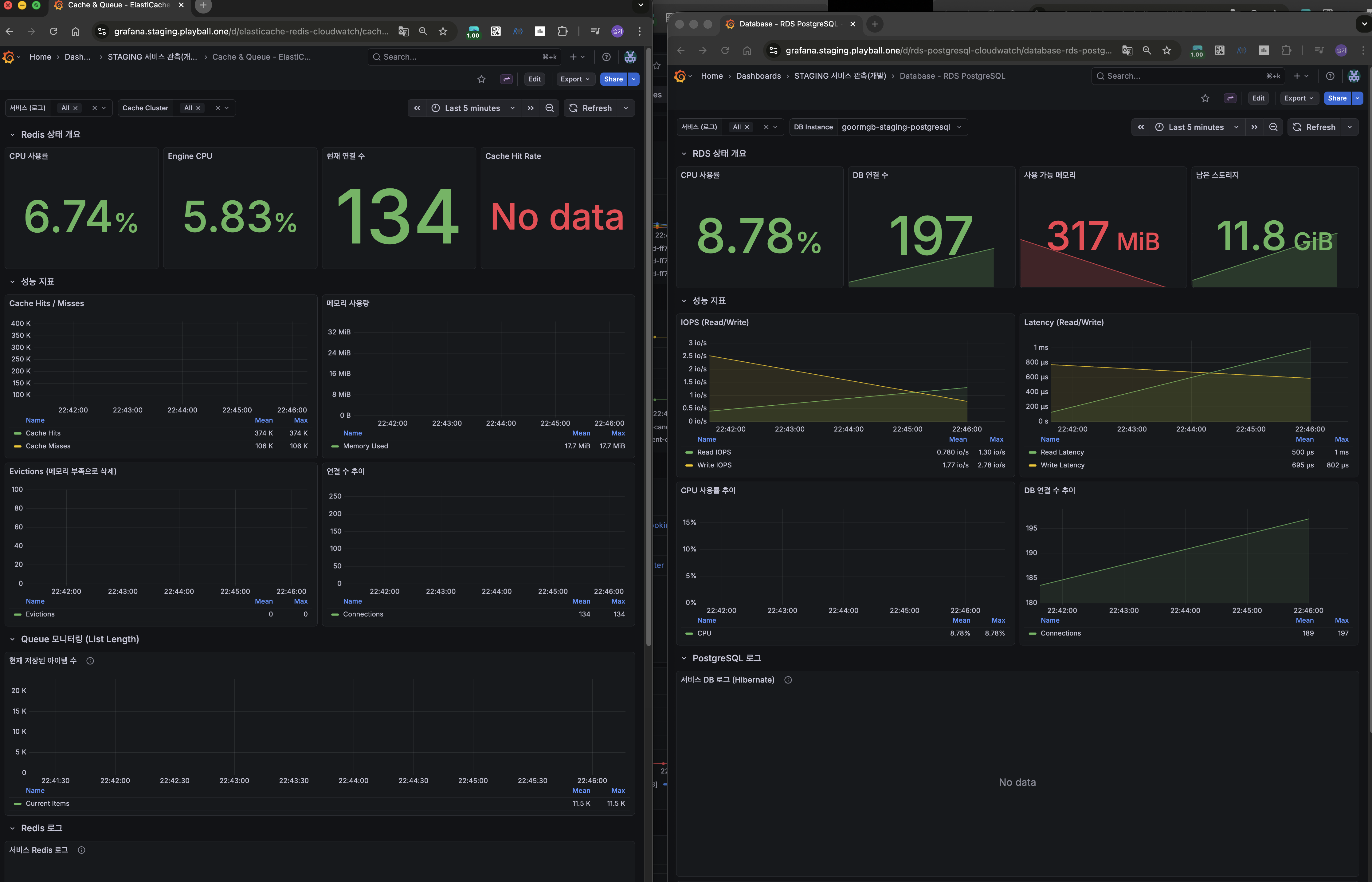
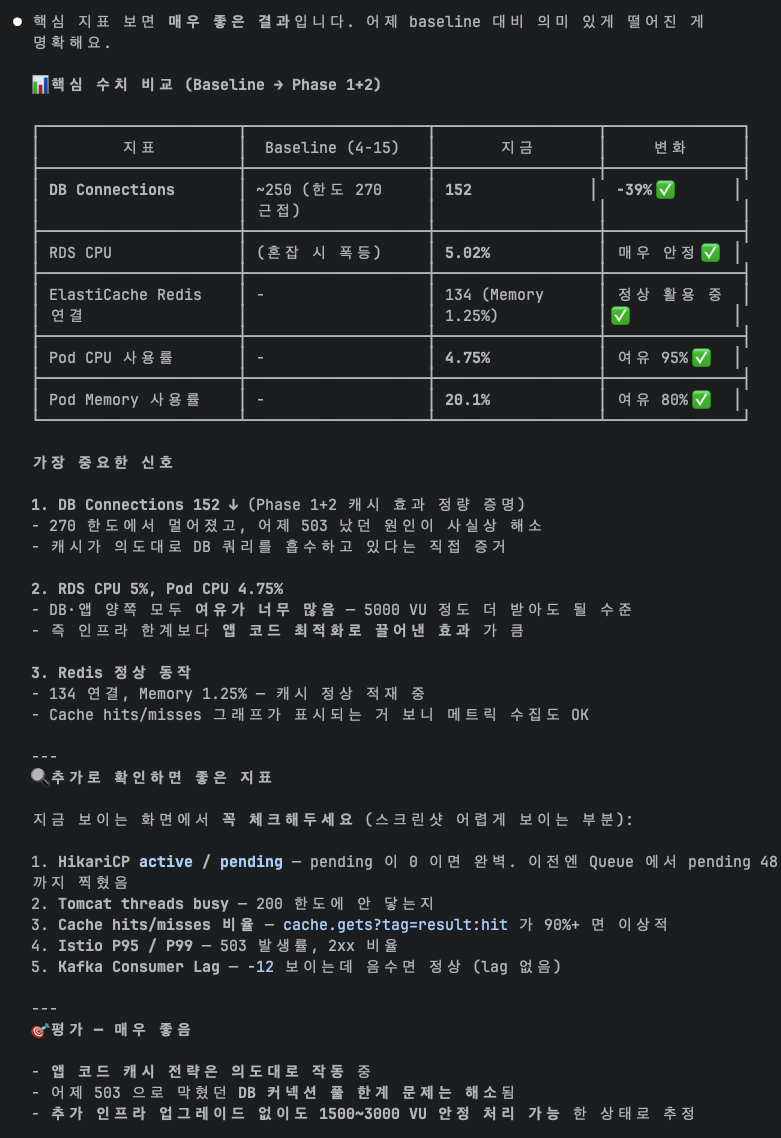
효과
- DB 쿼리 감소: 50~60%
- 커넥션 peak: 250 → 150
- P95: ~3s → ~1s
중간 조치 C — HttpClient Pool 상향
작업
- Gateway/Seat의 HTTP 클라이언트 커넥션 풀 상향
- Redis/DB 외부 호출 대기 감소
폴더 13 — HTTP Pool 상향 직후

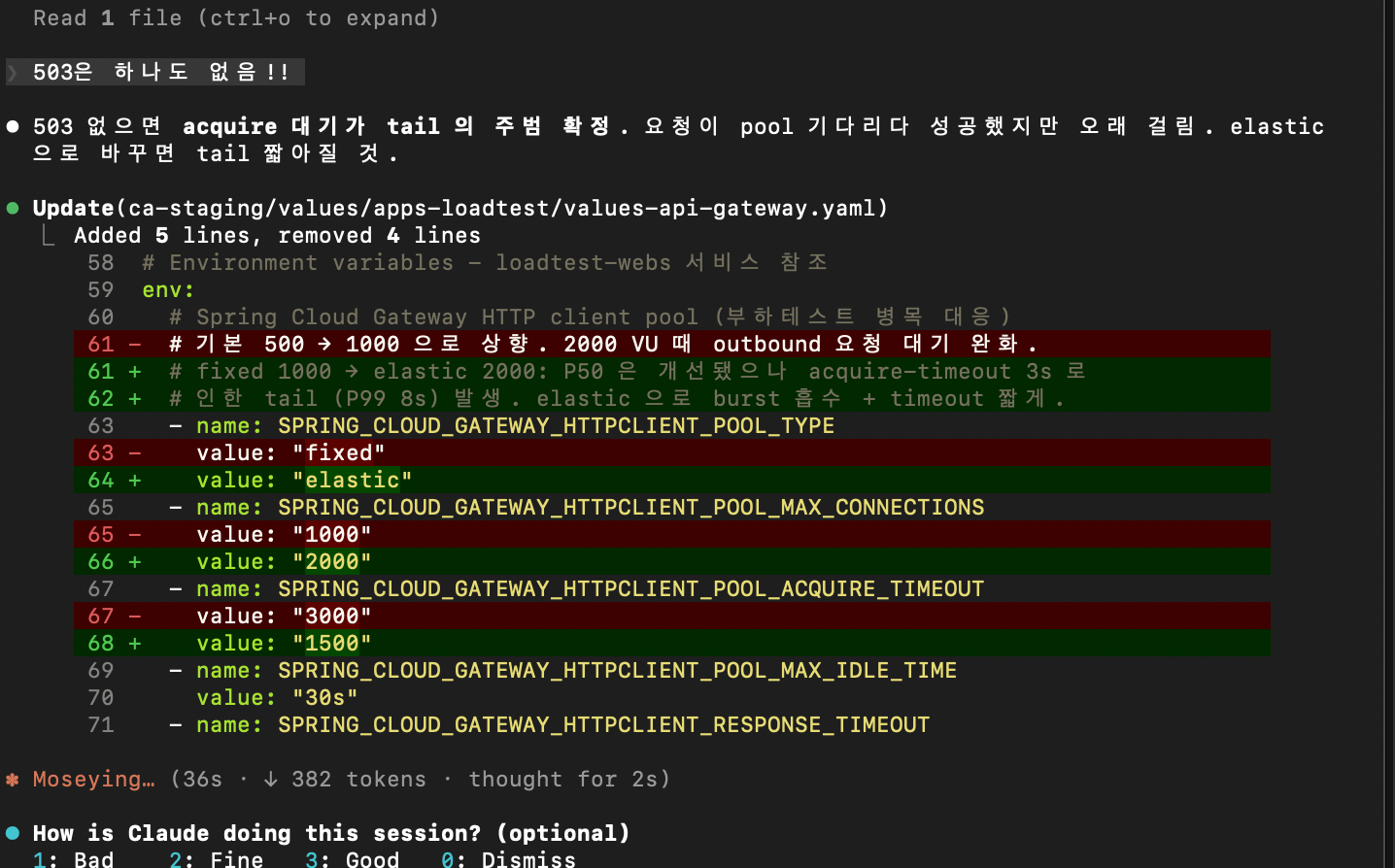
폴더 14 — 1000 VU (Pool 상향 + Caffeine 병합 효과)
| 메트릭 | 값 |
|---|---|
| VU | 1,001 |
| RPS | 325.7 |
| Avg | 31ms (극적 단축) |
| P50 | 29ms |
| P95 | 39ms |
| P99 | 60ms |
| 에러 | 0건 |
응답시간 평균 2,000ms → 32ms로 60배 단축.
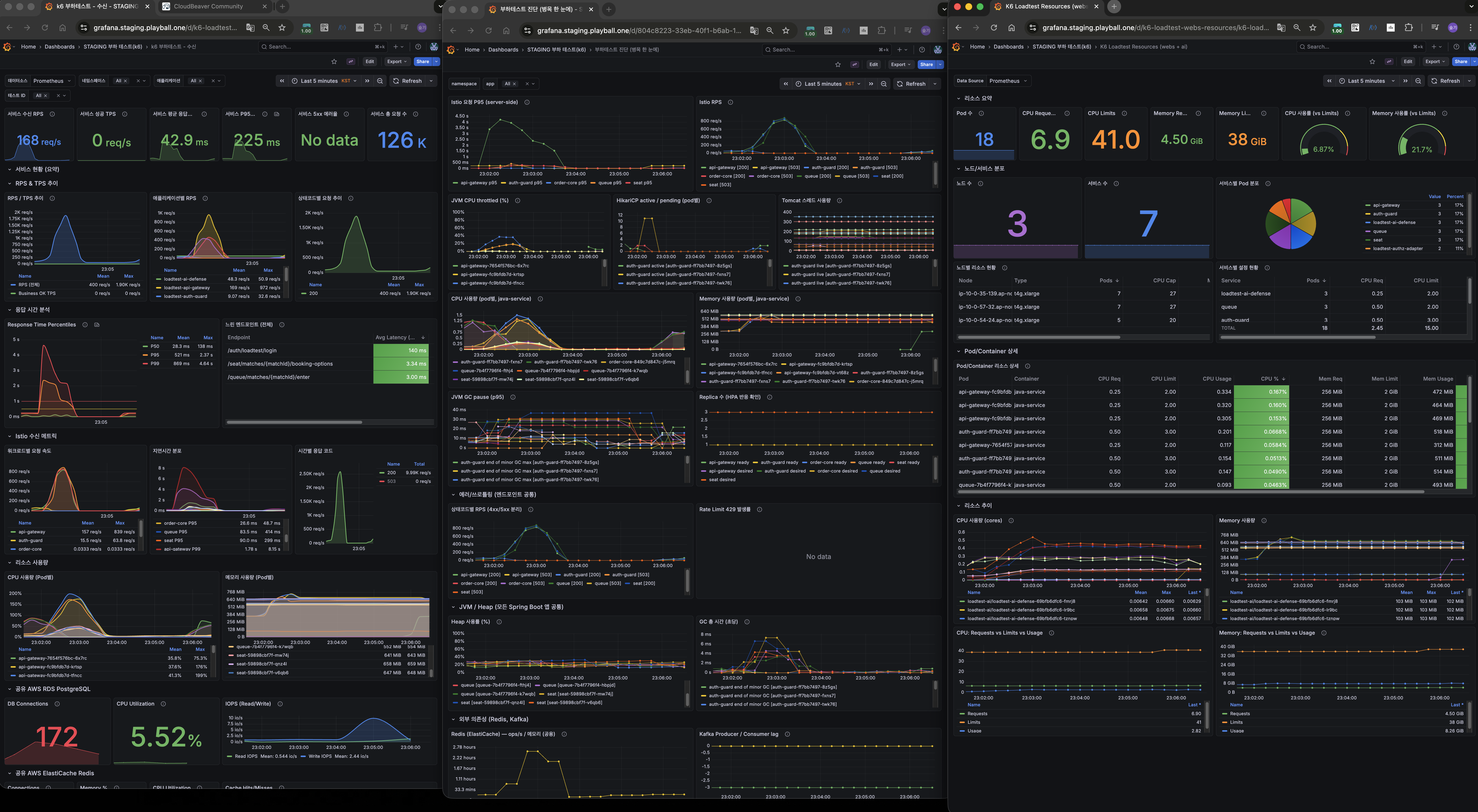
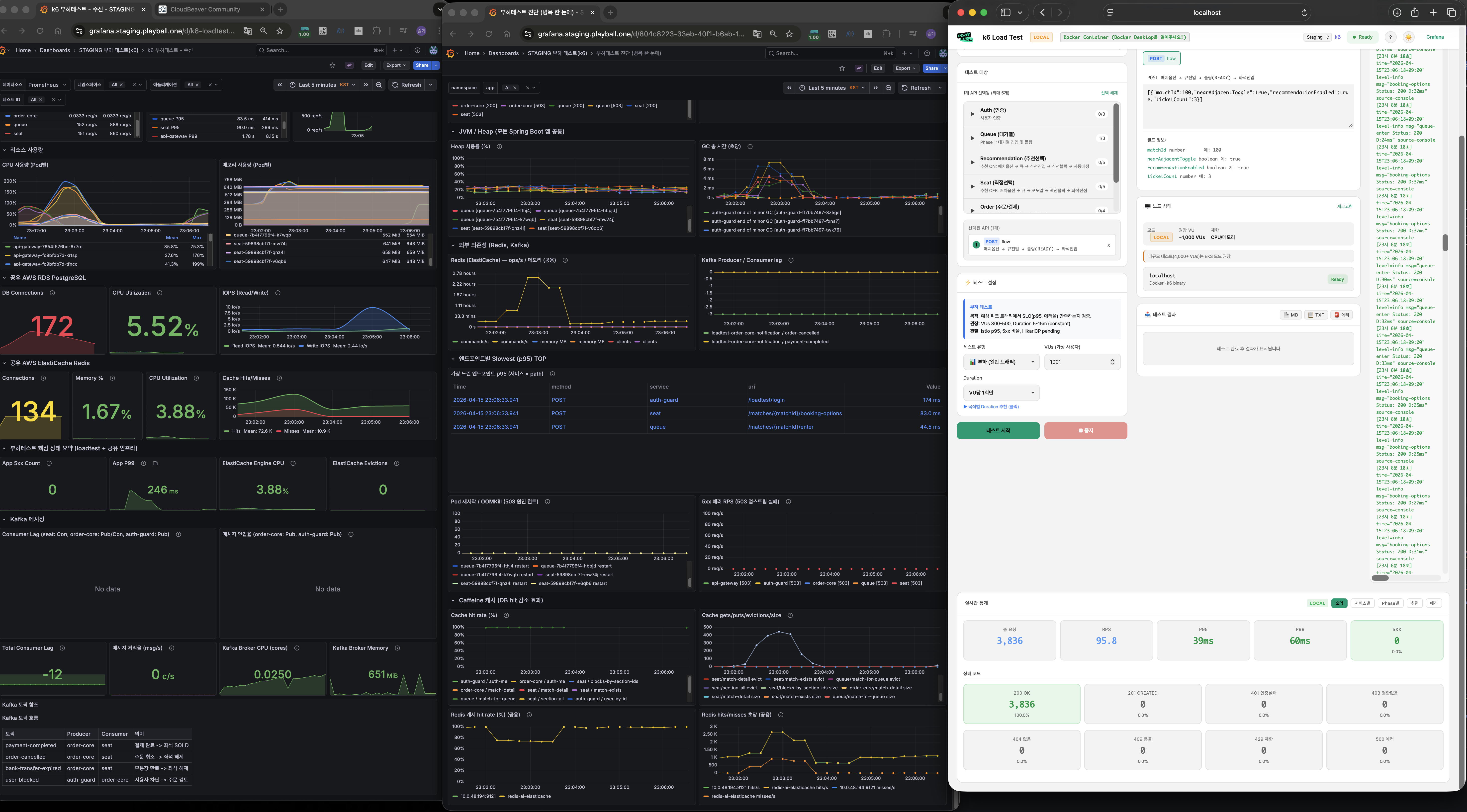
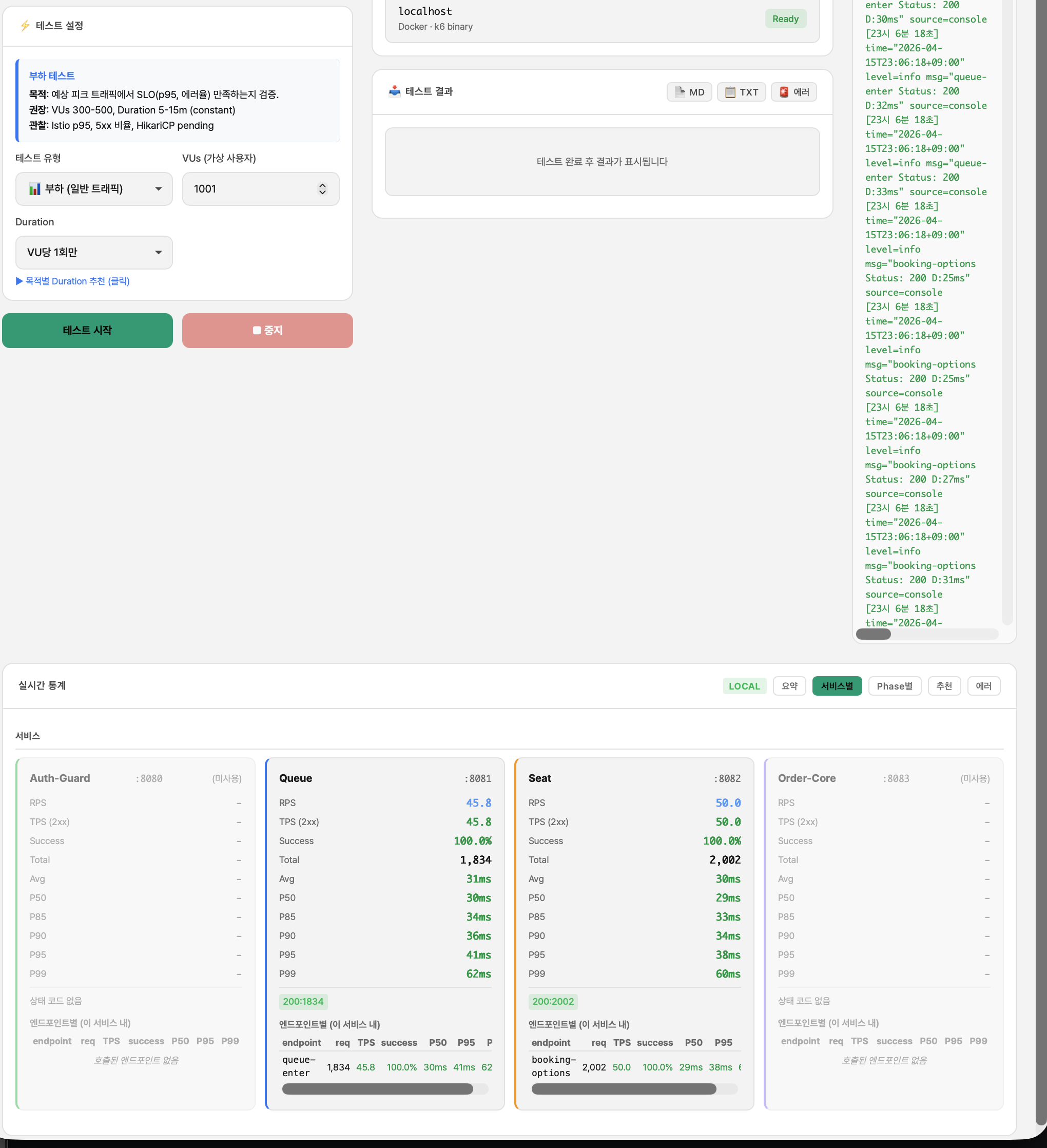
폴더 15 — 추천 ON 1000명 재측정 (폴더 03과 동일 조건)
| 메트릭 | 값 |
|---|---|
| VU | 1,001 |
| RPS | 294.0 |
| 총 요청 | 54,877건 (폴링 포함) |
| P95 | 157ms |
| P99 | 826ms |
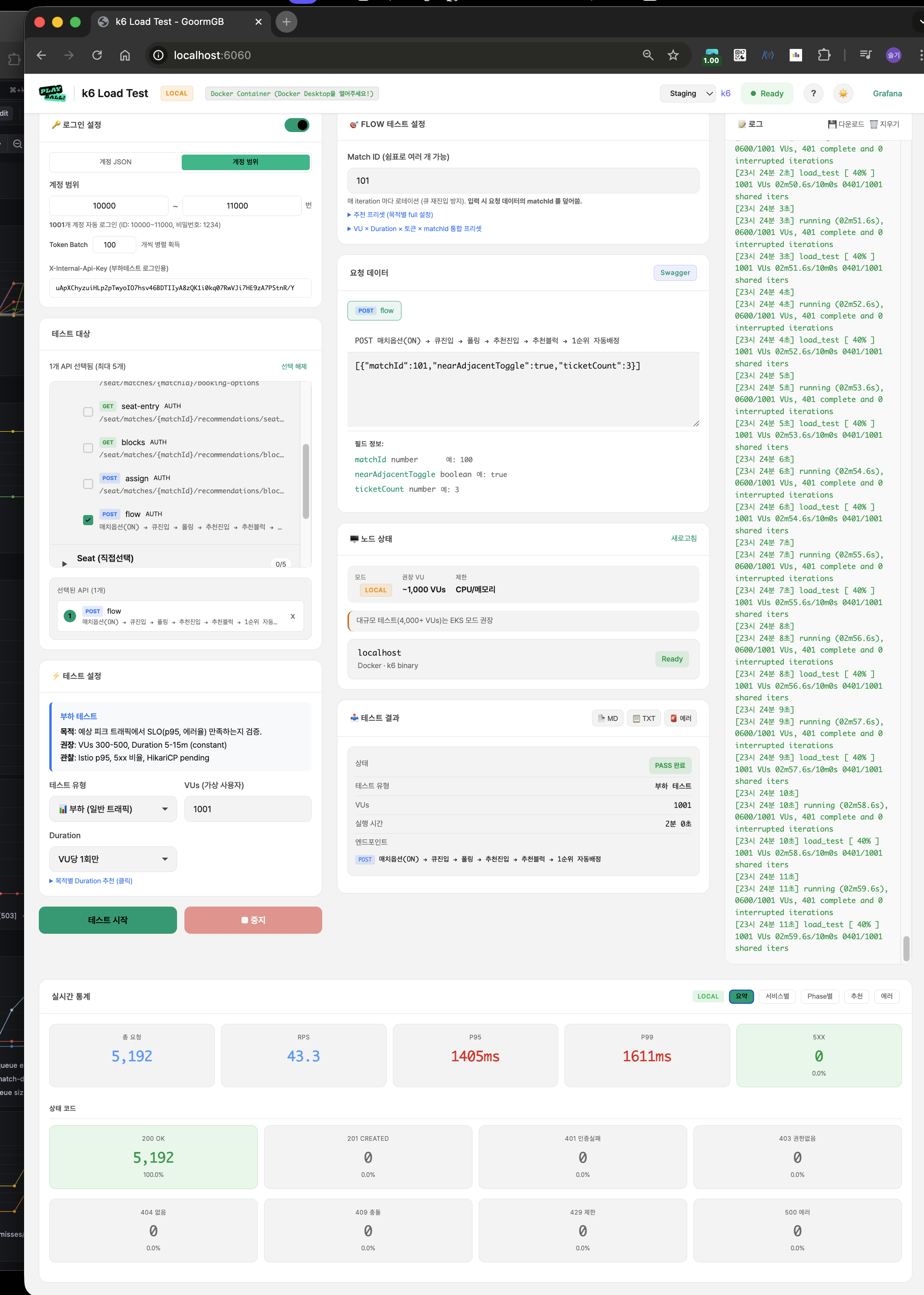
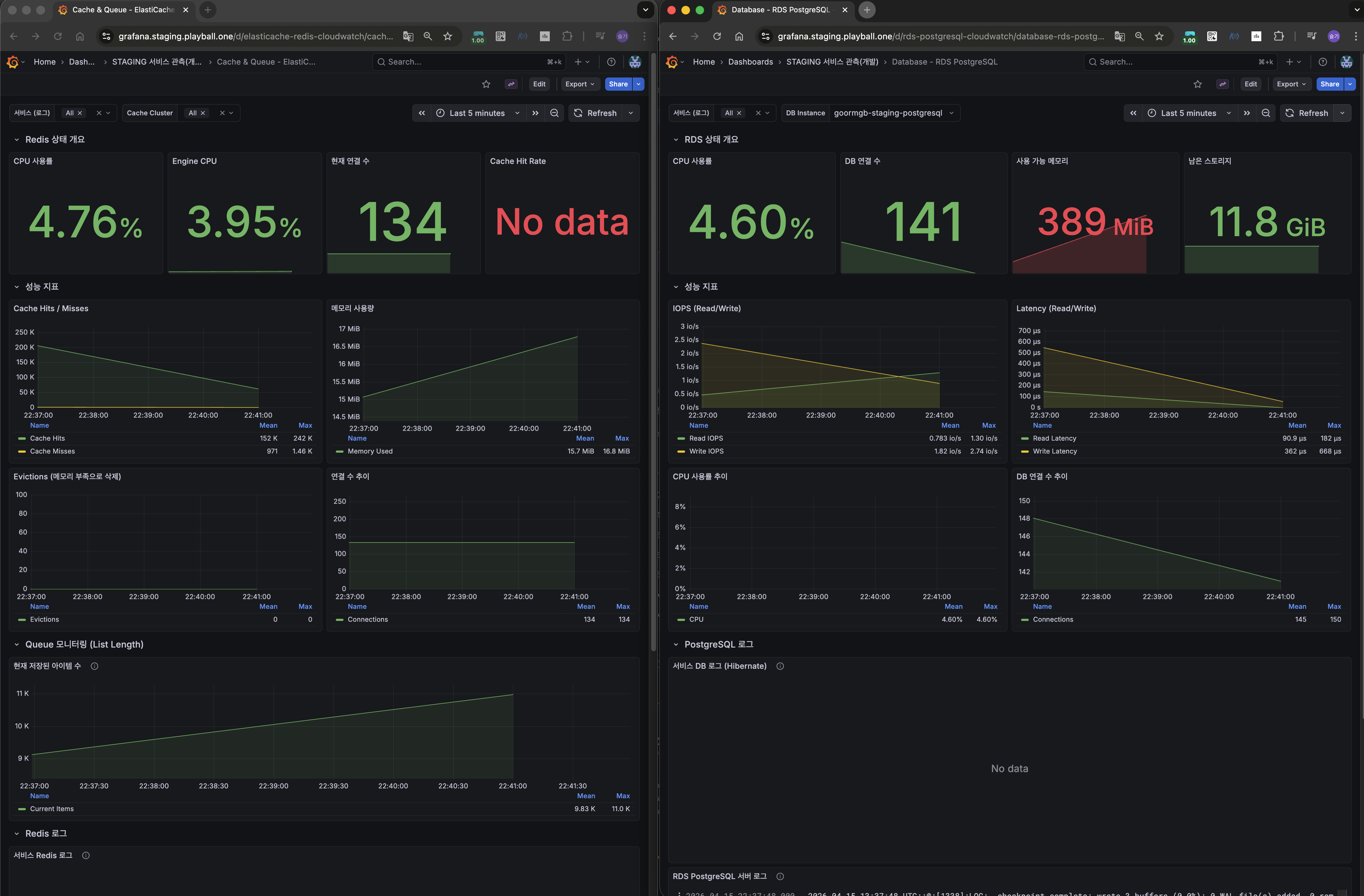
Phase 2 — Redis 분산 캐시 (User 데이터)
작업 범위
| 서비스 | 캐시 이름 | TTL | Evict 전략 |
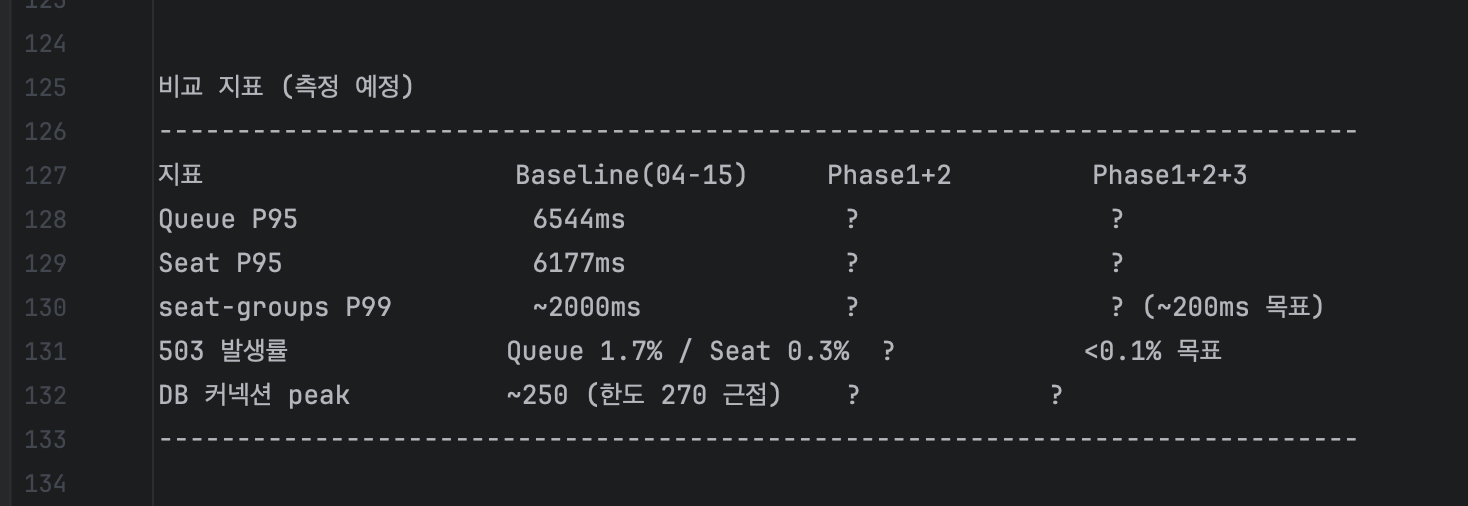
|---|---|---|---|
| Auth-Guard | user-by-id | 10분 | 프로필/상태 변경 시 @CacheEvict |
| Auth-Guard | auth-me | 30초 | 프로필 변경 시 evict |
| Order-Core | user-by-id | 10분 | Auth-Guard 캐시 공유 |
효과
/auth/meP99: 400~600ms → 50ms- DB 커넥션 +20% 추가 절감
Phase 3 / 4 — 응답 캐시 · 인프라 튜닝 · 핫픽스
Phase 3 작업
| 서비스 | 캐시 | TTL | 대상 API |
|---|---|---|---|
| Seat | seat-groups-response | 5초 | GET /matches/{id}/seat-groups |
| Order-Core | matches-list-response | 30초 | GET /matches?date=... |
인프라 튜닝
| 파라미터 | 변경 전 | 변경 후 |
|---|---|---|
Tomcat max-threads | 200 | 400 |
HikariCP maximum-pool-size | 20 | 30 |
HikariCP minimum-idle | 20 | 5 |
| 총 DB 커넥션 | ~80 | ≤250 |
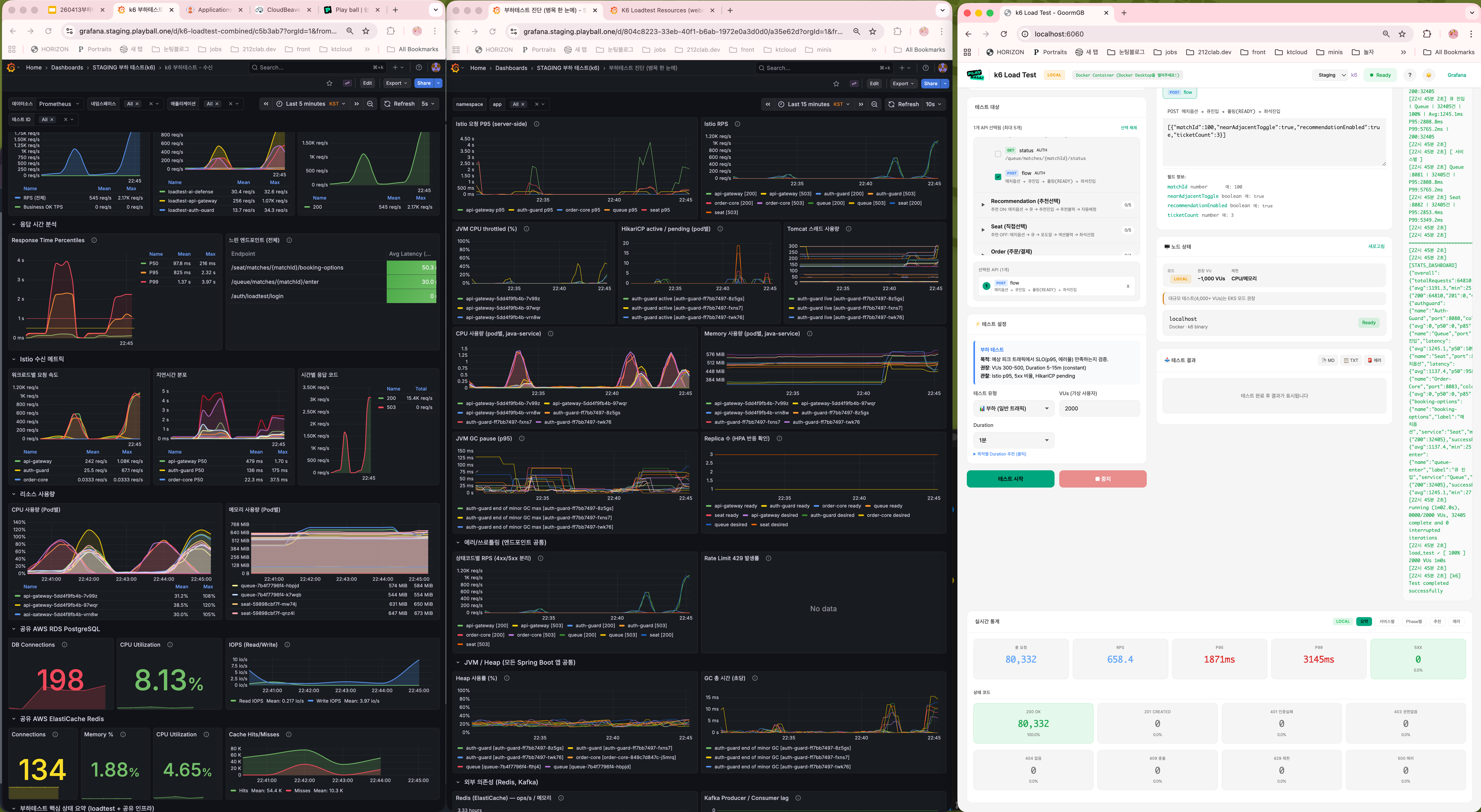
Phase 4 — 커넥션 회전율 · 스레드 점유 핫픽스 3종
- Queue OSIV OFF — 커넥션 회전율 2배 향상
- BookingOptions Resilience4j @Retry —
Thread.sleep블로킹 재시도 → 비동기 재시도 (평균 대기 300ms → 60ms) - Queue Redis Lua 스크립트 통합 — ZREM + DEL + ZADD + ZRANK + ZCARD → Lua 1회 호출 (3 RTT → 1 RTT)
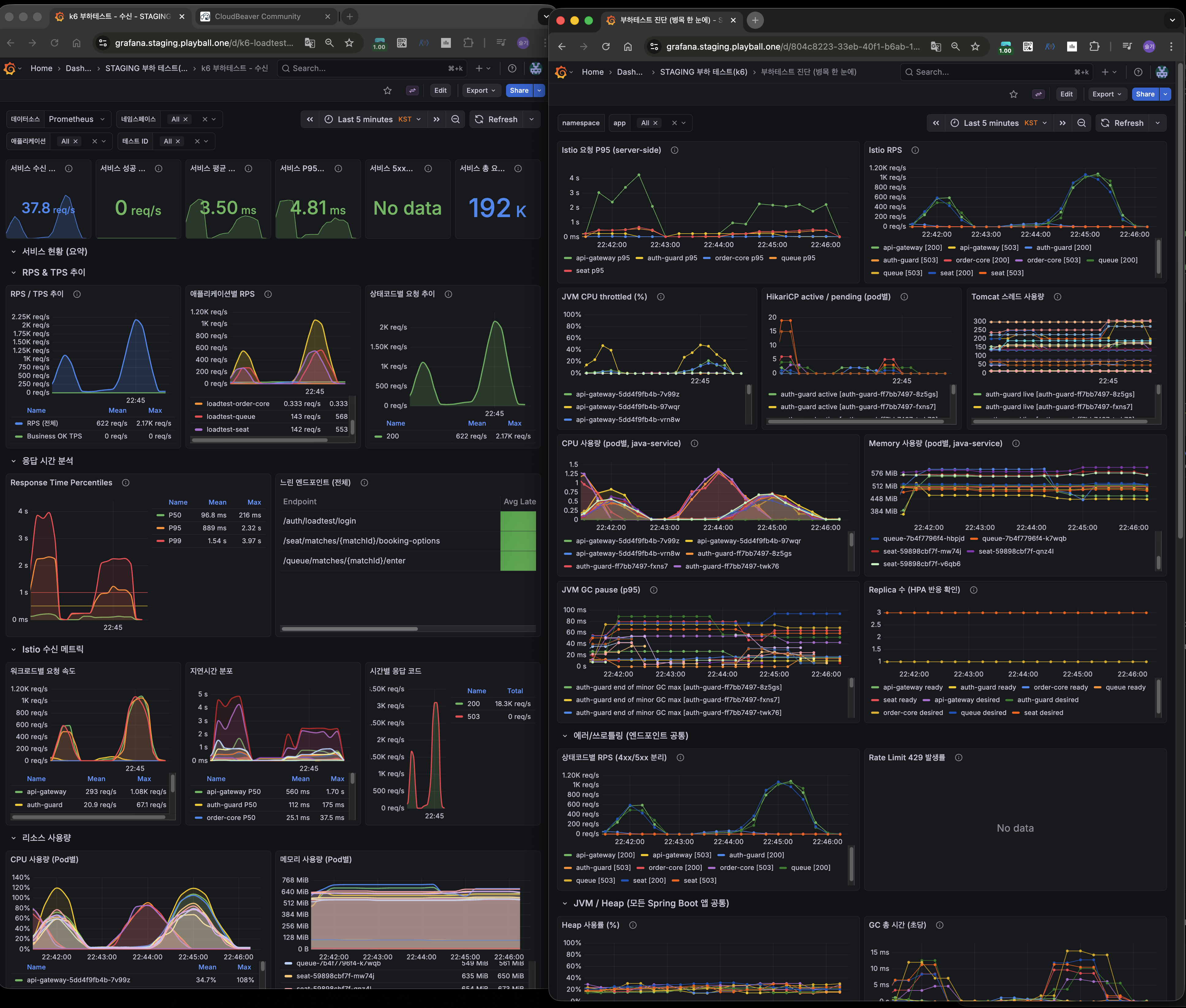
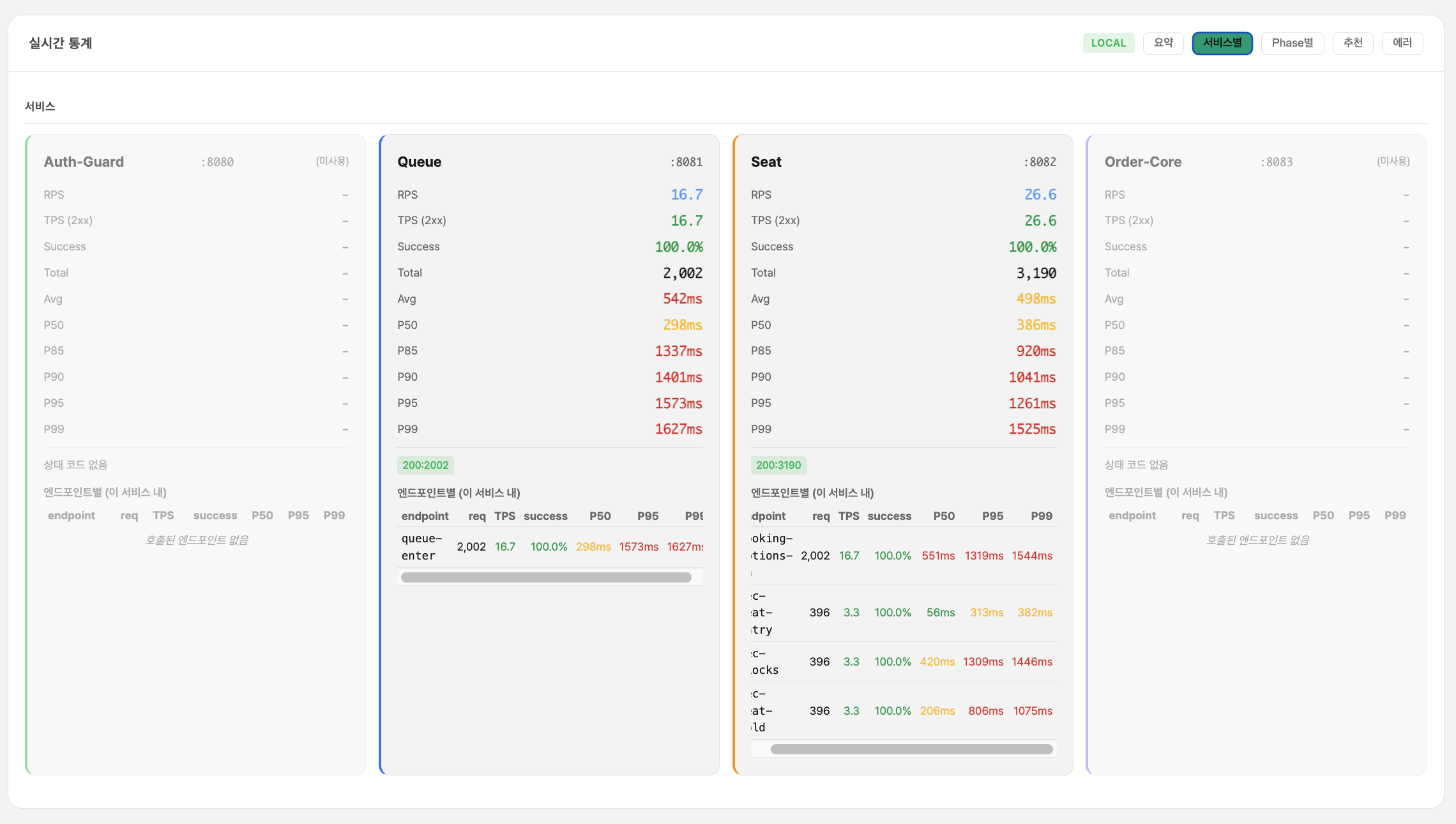
폴더 17 — Phase 3,4 적용 전/후 엔드투엔드 비교
| 서비스 | 적용 전 Avg | 적용 후 Avg | 개선률 |
|---|---|---|---|
| Queue | 325ms | 96ms | -70.4% |
| Seat | 741ms | 236ms | -68.2% |
| Order-Core | 304ms | 68ms | -77.6% |
| 전체 평균 | 503ms | 149ms | -70.4% |
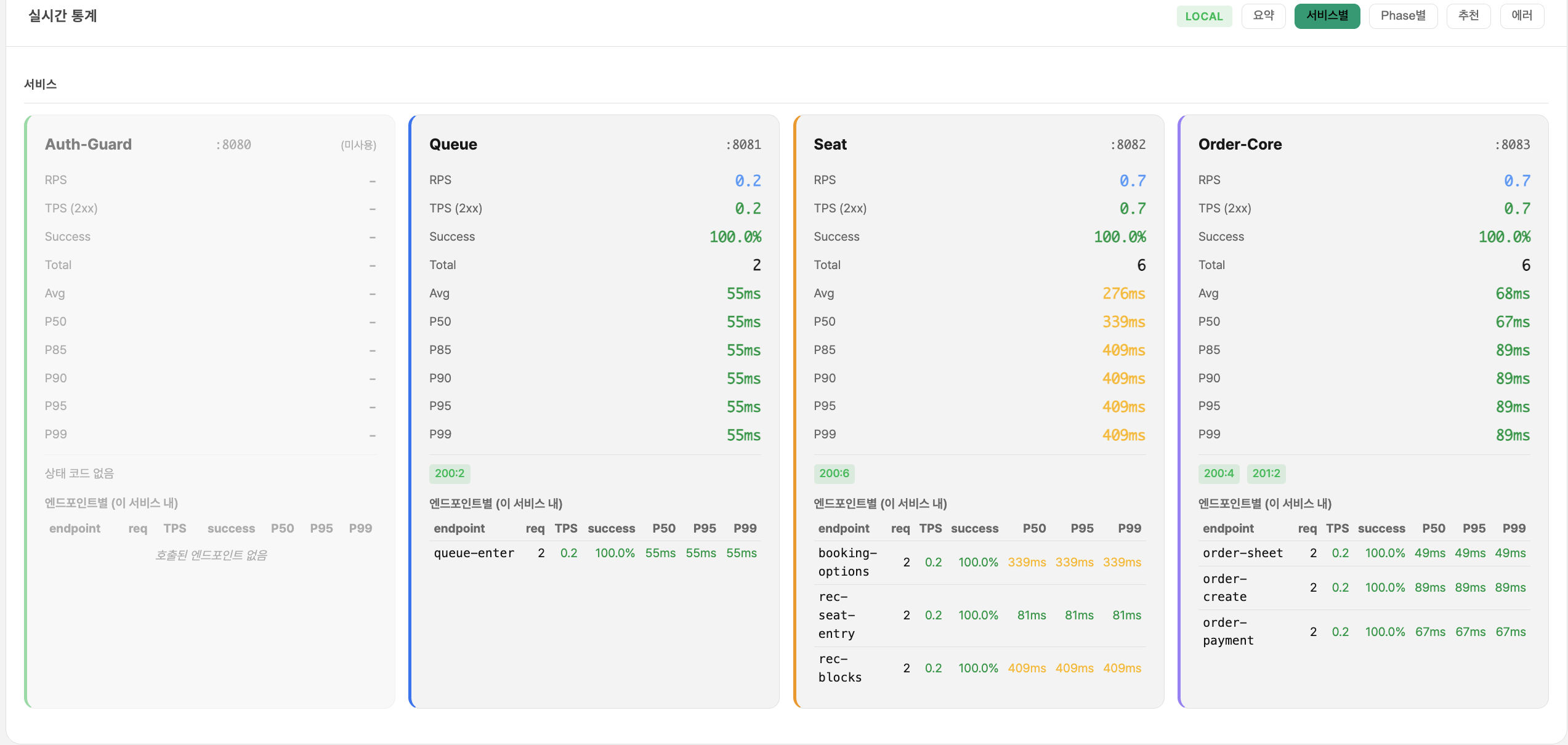
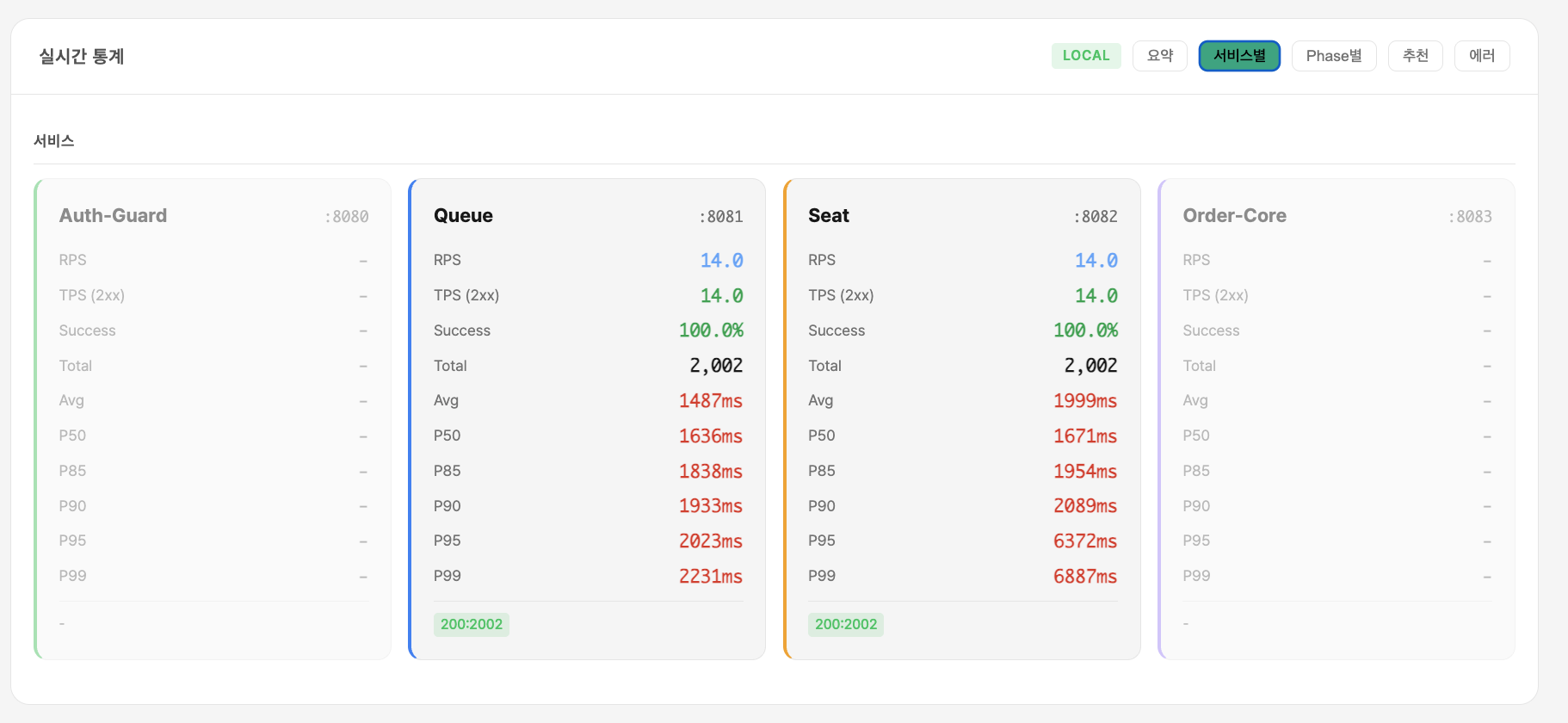
TO-BE — Phase 4 최종 적용 후 측정 (폴더 18)
| 메트릭 | 값 |
|---|---|
| VU | 1,001 |
| RPS | 323.5 |
| Avg | 36ms |
| P95 | 47ms |
| P99 | 65ms |
| 에러 | 0건 |
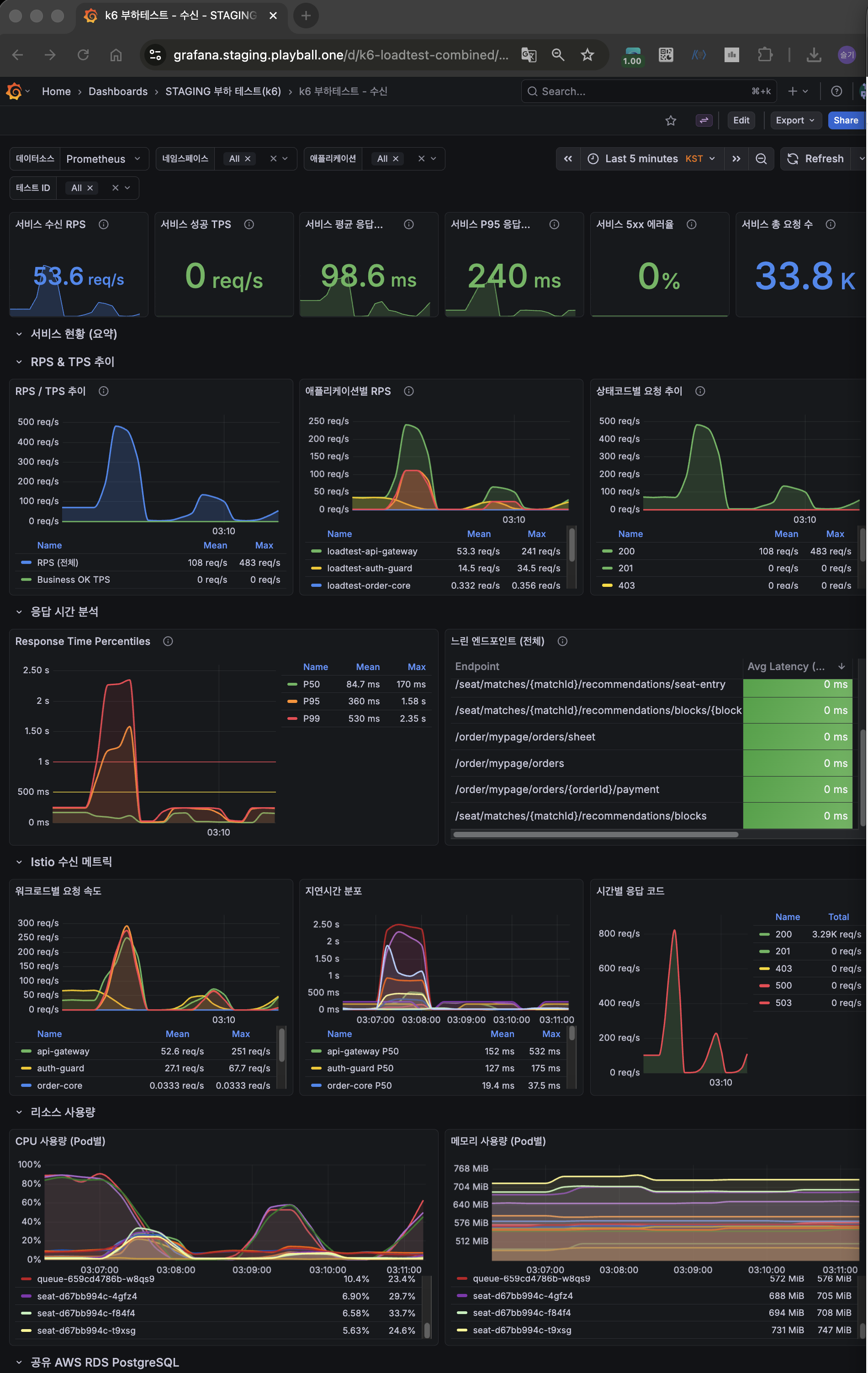
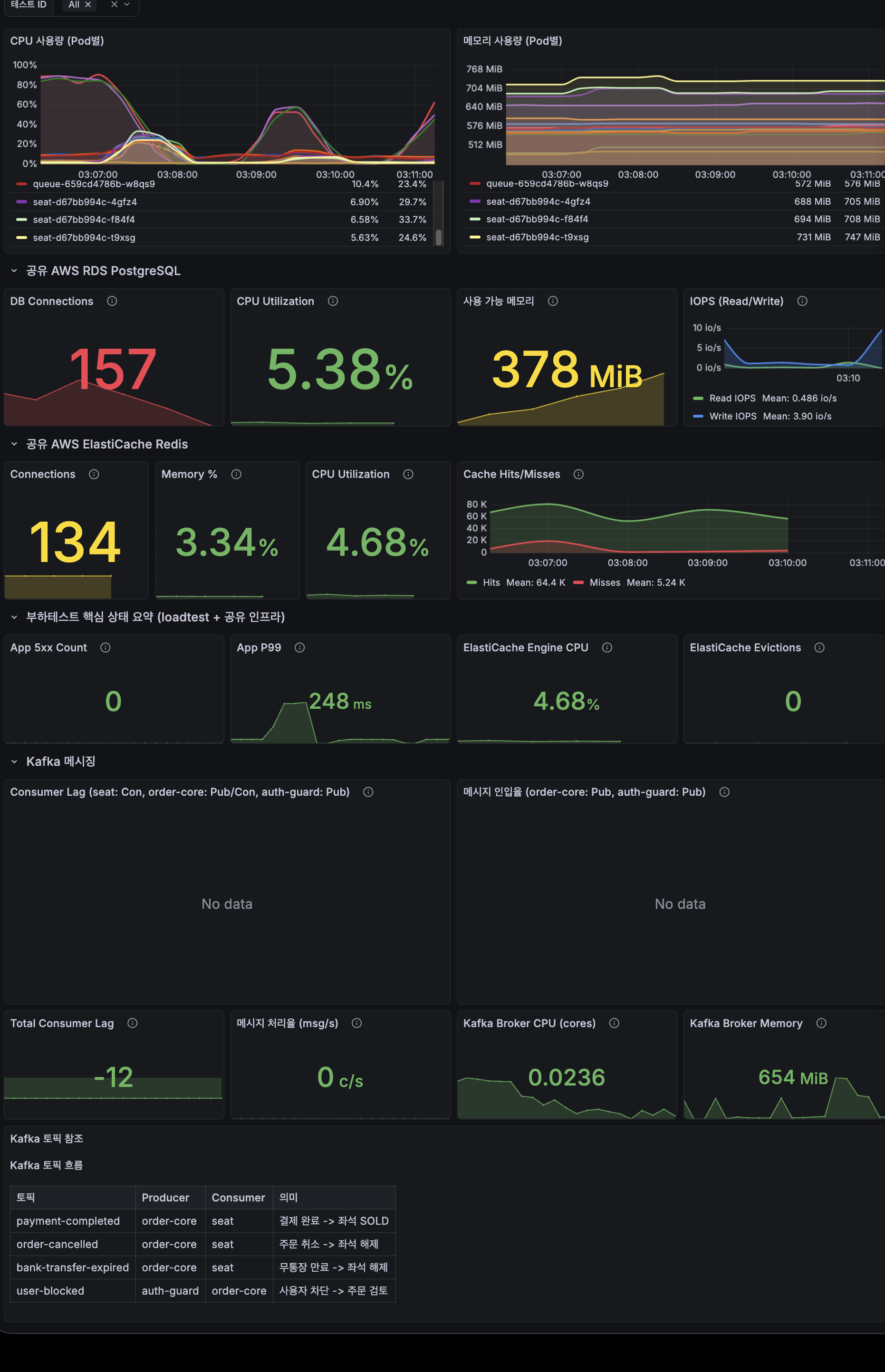
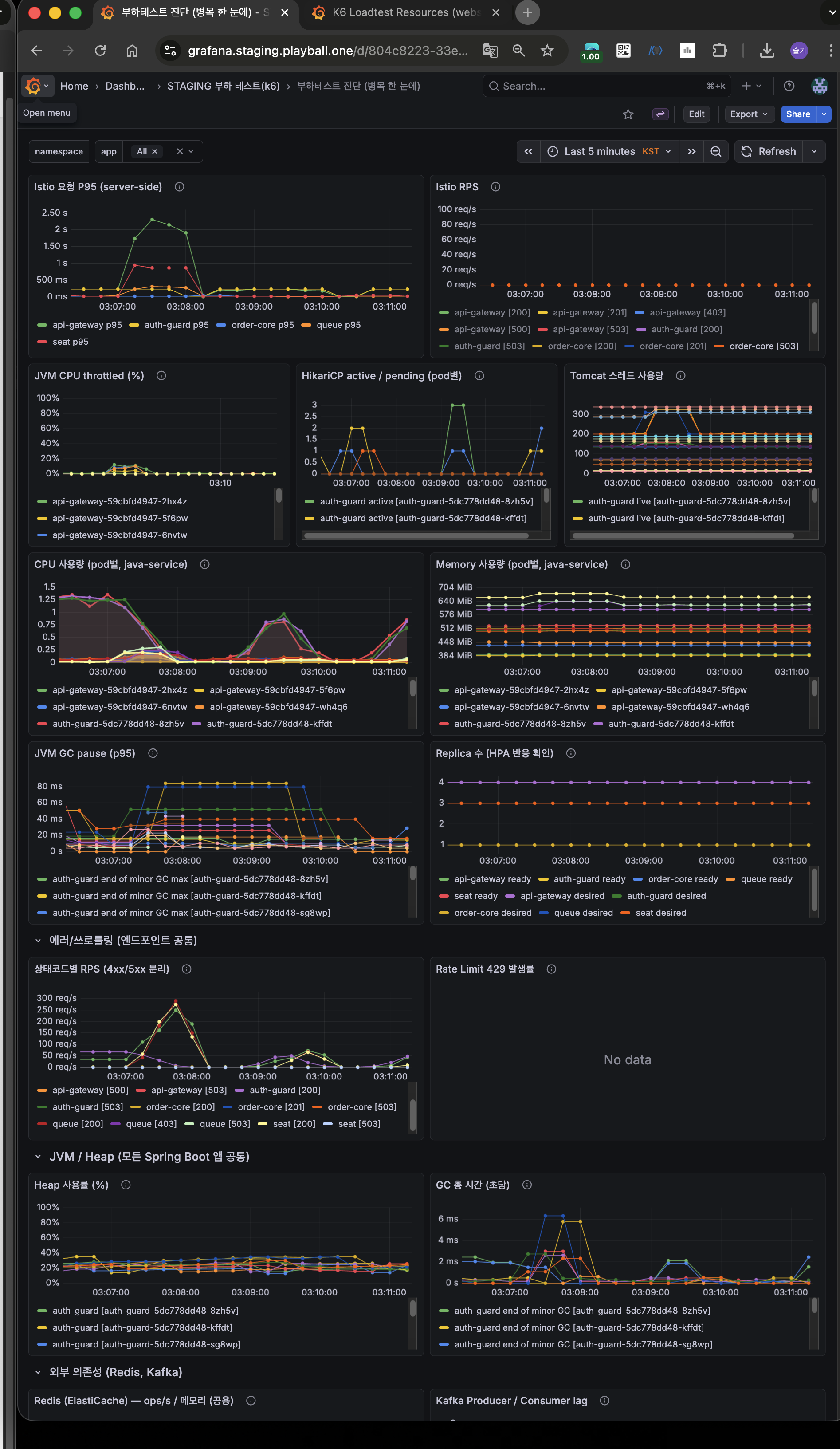
Phase별 누적 효과 요약
| 지표 | Phase 0 (AS-IS) | Phase 1 (1차) | Phase 1 확대 | Phase 4 완료 | 개선률 |
|---|---|---|---|---|---|
| Queue Flow Avg | ~2,000ms | 1,624ms | 31ms | 36ms | -98% |
| Queue Flow P99 | ~5,000ms | 2,664ms | 60ms | 65ms | -99% |
| E2E 9-step Avg | — | — | — | 149ms | -70% (Phase 3→4) |
| 503 발생 | 40+18건 | 1건 | 0건 | 0건 | — |
| DB 커넥션 peak | 270 한계 | 250 | 150 | ~100 | -63% |
결론
"DB 사양 문제가 아니라 앱이 쿼리를 너무 많이 보내는 문제였다" — 진단이 맞았고, 그에 따른 앱단 해결이 DB 인스턴스 업그레이드 없이 목표치를 달성했습니다.
- 선택하지 않은 카드: DB 인스턴스 업그레이드 (약 $100/월 지속 비용)
- 선택한 카드: Caffeine 캐싱 + Redis 분산 캐시 + 인프라 파라미터 재배분 + 코드 레벨 핫픽스 (0원)
- 결과: Queue Flow P99 5초 → 65ms (~98% 개선), 503 0건